
Kubernetes multi-cloud avec Scaleway Kosmos
Déployer Kubernetes est devenu, depuis maintenant quelques années, relativement facile. Non pas parce que Kubernetes est devenu plus simple mais parce que des outils/produits sont venus combler ce problème de déploiement. On va retrouver des outils comme Kubeadm, l’outil officiel pour bootstraper un cluster Kubernetes, des solutions comme Symplegma, des outils pour installer Kubernetes en local mais encore et surtout des services managés chez les principaux Cloud Providers, ce qui permet désormais via quelques clics ou un script Terraform de déployer nos clusters Kubernetes.
Scaleway fait partie de ces Providers et fournit depuis un peu plus d’un an la solution Kubernetes Kapsule.
Avoir un cluster Kubernetes sur AWS, GCP, Azure ou Scaleway n’est donc pas un problème.
Mais en revanche, en avoir à plusieurs endroits et les faire travailler ensemble, ça, c’est un challenge.
Kubernetes multi cloud
Voici donc le prochain champ de bataille, le multi-cloud. Tout le monde en parle, peu en font car techniquement rien n’est simple en réalité.
Lors du dernier re:Invent, AWS annonçait EKS Distro et EKS anywhere, deux solutions (dont on attend toujours la sortie de la seconde ^^) permettant de porter EKS (le Kubernetes managé d’AWS) en dehors d’AWS. Dans les faits, EKS Distro n’est en réalité qu’une série d’images OCI permettant de reproduire le control plane d’EKS sur n’importe quelle machine. Il n’y a pas d’intéraction entre cette machine et le control plane EKS hébergé chez AWS. Cette intéraction doit être le fruit du futur EKS anywhere. Google Anthos vise aussi à étendre le champ d’application de GKE (le Kubernetes managé de GCP) et à déborder au-delà de GCP.
Une autre solution, native à Kubernetes, est la fédération de clusters. Il s’agit de créer un “meta cluster” qui agrège d’autres clusters pour n’en former qu’un seul. Chaque cluster est vu comme un node unique du méta cluster et le scheduling se fait en deux étapes, une première pour sélectionner le cluster puis une deuxième pour choisir le node au sein du cluster. La fédération de cluster demande d’avoir accès au control plane de Kubernetes ou au moins d’avoir un minimum de contrôle sur sa configuration, ce qui limite son implémentation sur les Kubernetes managés où par définition vous n’avez pas accès au control plane. C’est donc une solution plutôt tournée vers les clusters on-premise ou non managés. Nous parlons de sa mise en place avec EKS.
Aujourd’hui, Scaleway annonce l’ouverture de la béta privée de son service Kosmos, concurrent direct d’EKS Anywhere et de Google Anthos.
Scaleway Kosmos
Kosmos doit être vu comme une surcouche à Kubernetes Kapsule, il permet non pas d’exporter Kapsule sur un autre cloud provider ou on-premise mais il permet de transformer n’importe quelle machine en un node Kubernetes Kapsule. Contrairement à la fédération de clusters où plusieurs clusters indépendants se mettent à travailler ensemble, ici il n’y a qu’un seul cluster, un seul control plane, celui hébergé chez Scaleway.
La communication entre le control plane Scaleway et les nodes (qu’ils soient chez Scaleway ou non est assuré par Kilo, un network overlay basé sur Wireguard, une solution moderne de VPN. Peu d’info ont circulé sur les détails de l’implémentation technique.
Déploiement
Le service étant en beta privée, il n’est pas encore disponible via Terraform, nous allons donc effectuer un déploiement à la main via la console Scaleway.
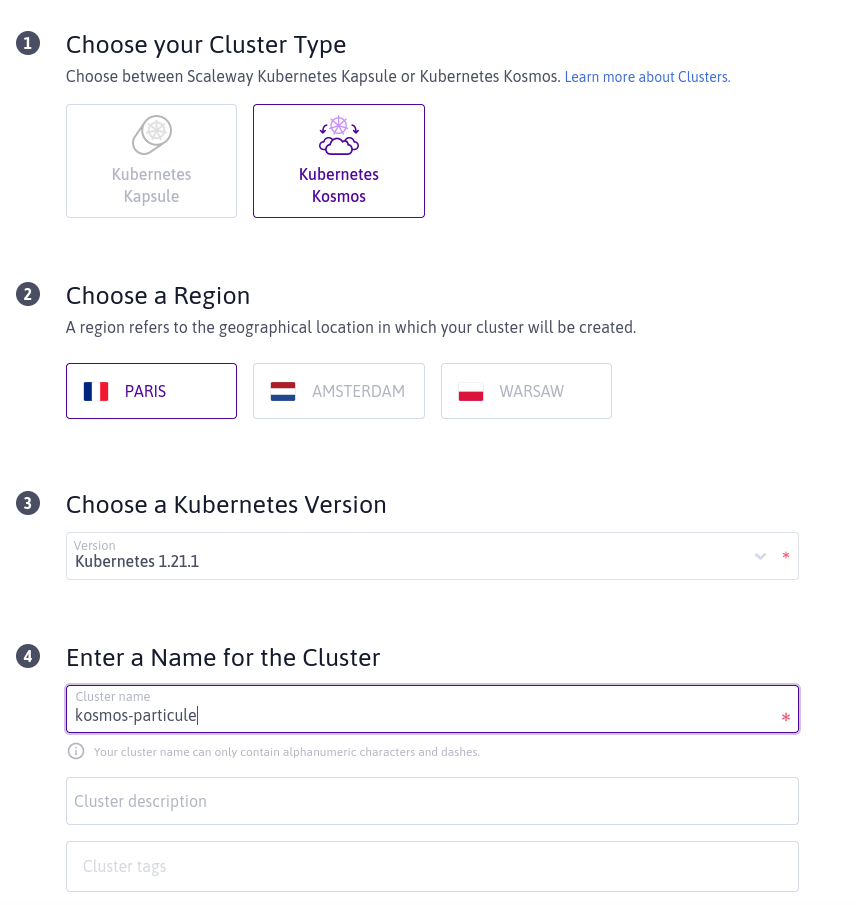
Puis on peut configurer le premier pool de notre cluster. Et là, première nouveauté, nous pouvons choisir une région différente de notre cluster. Ici on a choisi de mettre notre cluster dans la région FR-PAR (le control plane en réalité) mais on choisi de mettre notre premier pool dans la zone AMS-1
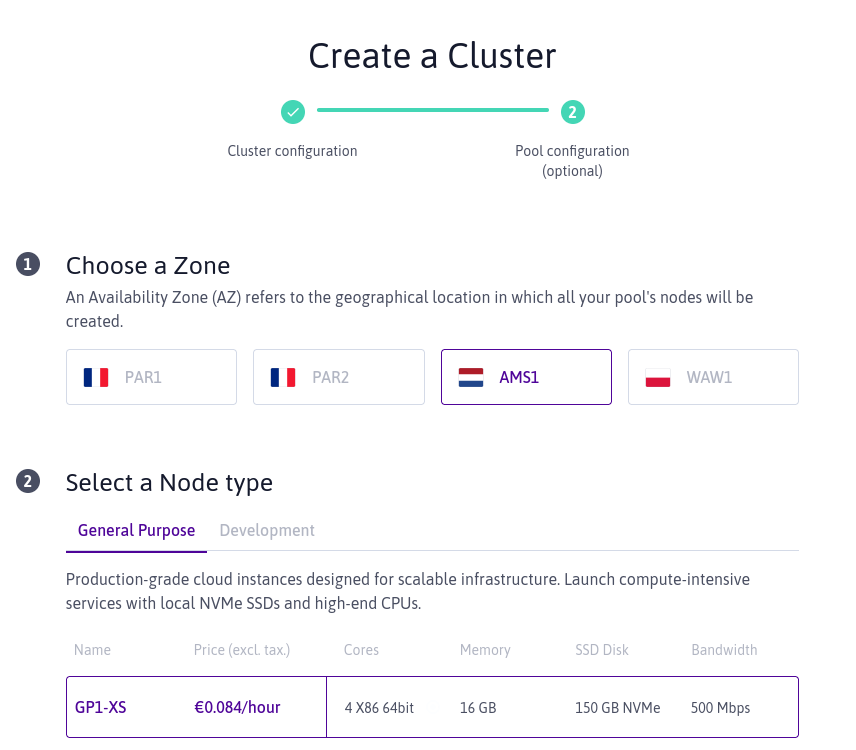
En attendant que tout soit crée chez Scaleway, nous allons créer un second pool dans une autre zone.
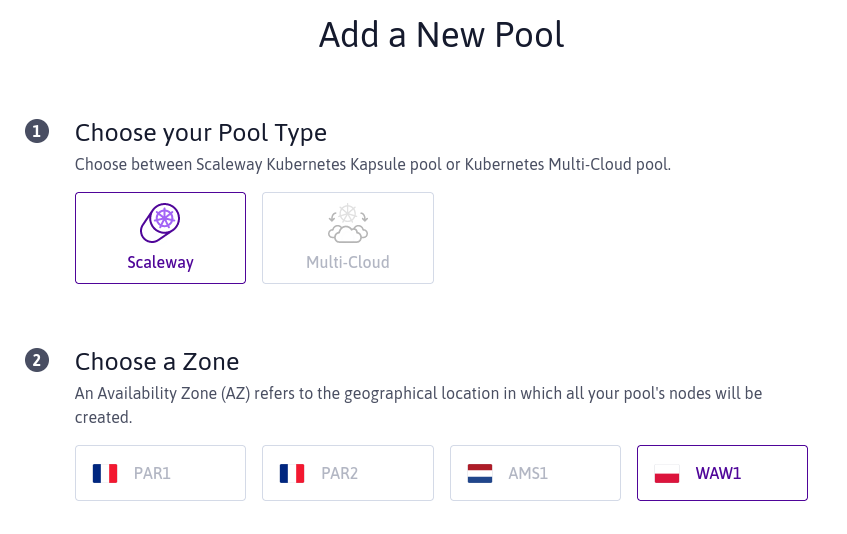
On voit que nous avons un nouveau choix ici Scaleway et Multi-Cloud.
L’option Scaleway permet de schéduler un pool sur l’infrastructure Scaleway,
comme notre premier pool. L’option Multi-Cloud permet de schéduler un node
n’importe où dans le monde. On y revient dans 5 min, promis.
Pour ce nouveau pool, j’ai choisi la zone WAW-1.
Récupérons le kubeconfig de notre cluster pour nous y connecter et vérifier que tous nos pools sont bel et bien créés.
$ kubectl get node
NAME STATUS ROLES AGE VERSION
scw-kosmos-particul-pool-quirky-lederbe-2cc069 Ready <none> 102s v1.21.1
scw-kosmos-particule-default-ca8e9028f1b745698 Ready <none> 7m41s v1.21.1
$ kubectl describe node scw-kosmos-particul-pool-quirky-lederbe-2cc069
Name: scw-kosmos-particul-pool-quirky-lederbe-2cc069
Roles: <none>
Labels: failure-domain.beta.kubernetes.io/region=pl-waw
failure-domain.beta.kubernetes.io/zone=pl-waw-1
$ kubectl describe node scw-kosmos-particule-default-ca8e9028f1b745698
Name: scw-kosmos-particule-default-ca8e9028f1b745698
Roles: <none>
Labels: failure-domain.beta.kubernetes.io/region=nl-ams
failure-domain.beta.kubernetes.io/zone=nl-ams-1
On voit bien que nos nodes sont bien situés dans des zones de disponibilité différentes et que nous pouvons utiliser cette information pour effectuer un schéduling intelligent.
Multi Cloud pour de vrai
Nous avons donc un cluster Kubernetes managé multi AZ mais toujours au sein du
même cloud provider. Comme nous l’avons vu dans le screenshot précédent, on peut
cette fois ci utiliser l’option Multi-Cloud pour schéduler un node en dehors
de Scaleway.
Cela nous donne un pool vide dans lequel nous allons pouvoir ajouter des nodes.


J’en ai même crée un 4ème chez OVH.
Il suffit maintenant de créer une instance dans chacun de ces clouds puis de lancer les commandes données par Scaleway pour que ces instances rejoignent le cluster Kosmos.
root@ip-172-31-39-101:~# wget https://scwcontainermulticloud.s3.fr-par.scw.cloud/multicloud-init.sh && chmod +x multicloud-init.sh^C
root@ip-172-31-39-101:~# ./multicloud-init.sh -p 9d83ea05-f087-48b8-b89d-4e7ea3f28a87 -r PAR -t $SCWTOKEN
[2021-07-06 13:02:16] apt prerequisites: installing apt dependencies (0) [OK]
[2021-07-06 13:02:34] containerd: installing containerd (0) [OK]
[2021-07-06 13:02:34] multicloud node: getting public ip (0) [OK]
[2021-07-06 13:02:35] kubernetes prerequisites: installing and configuring kubelet (0) [OK]
[2021-07-06 13:02:35] multicloud node: configuring this a node as a kubernetes node (0) [OK]
Et au final (après une dizaine de minutes) on se retrouve avec :
$ kubectl get node
NAME STATUS ROLES AGE VERSION
scw-kosmos-particul-pool-quirky-lederbe-2cc069 Ready <none> 59m v1.21.1
scw-kosmos-particule-default-ca8e9028f1b745698 Ready <none> 65m v1.21.1
scw-kosmos-particule-pool-aws-1-8f13ce647e914e Ready <none> 94s v1.21.1
scw-kosmos-particule-pool-ovh-1-418092d35df44e Ready <none> 3m11s v1.21.1
- 2 nodes chez Scaleway, un à Amsterdam, un à Varsovie
- 1 node chez OVH à Londres
- 1 node chez AWS en Ireland
Démonstration schéduling
Maintenant que nous avons un vrai cluster Kubernetes multi-cloud, nous allons pouvoir utiliser les fonctions natives de schéduling de Kubernetes pour augmenter la résilience de nos applications.
Plusieurs mécanismes au sein de Kubernetes pour faire de la ségrégation de ressources.
- NodeSelector
- (Anti)Affinité
- Taints/Tolerations
- Pod Topology Spread Constraints
L’idée de cette exemple est de réussir à schéduler nos pods partout pour avoir le maximum de résilience.
Commençons par utiliser la fonction d’anti-affinité.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: antiaff
spec:
replicas: 2
selector:
matchLabels:
app: demo-multi-cloud
template:
metadata:
labels:
app: demo-multi-cloud
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- demo-multi-cloud
topologyKey: "topology.kubernetes.io/region"
containers:
- name: alpha
image: particule/helloworld
ports:
- containerPort: 80
Ce manifest permet de schéduler 2 pods avec une règle d’anti-affinité
spécifiant que des pods ayant le label app=demo-multi-cloud ne peuvent pas se
retrouver sur des nodes possédant le même label
topology.kubernetes.io/region. Comme tous nos nodes sont sur des régions
différentes, cela sera facile à vérifier.
Voici le résultat :
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
antiaff-588dbdf6c7-dth7c 1/1 Running 0 27s 100.64.1.6 scw-kosmos-particul-pool-quirky-lederbe-2cc069 <none> <none>
antiaff-588dbdf6c7-rxr2w 1/1 Running 0 27s 100.64.0.8 scw-kosmos-particule-default-ca8e9028f1b745698 <none> <none>
Nous avons bien nos pods sur des régions différentes.
Mais que se passe t-il si nous souhaitons effectuer un scaling-up à 5 pods ?
$ kubectl scale deploy/antiaff --replicas=5
deployment.apps/antiaff scaled
$ k get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
antiaff-588dbdf6c7-dth7c 1/1 Running 0 2m51s 100.64.1.6 scw-kosmos-particul-pool-quirky-lederbe-2cc069 <none> <none>
antiaff-588dbdf6c7-psj9z 1/1 Running 0 12s 100.64.2.4 scw-kosmos-particule-pool-ovh-1-418092d35df44e <none> <none>
antiaff-588dbdf6c7-rxr2w 1/1 Running 0 2m51s 100.64.0.8 scw-kosmos-particule-default-ca8e9028f1b745698 <none> <none>
antiaff-588dbdf6c7-tcnjs 0/1 Pending 0 12s <none> <none> <none> <none>
antiaff-588dbdf6c7-vqvs7 1/1 Running 0 12s 100.64.3.4 scw-kosmos-particule-pool-aws-1-8f13ce647e914e <none> <none>
Un pod reste en Pending car il n’y a plus de node disponible.
L’anti-affinité est très efficace lorsque vous souhaitez volontairement éloigner des pods les uns des autres mais lorsque vous souhaitez répartir un groupe de pod de manière équitable entre plusieurs nodes/zones/régions, il faut utiliser la fonction de Pod Topology Spread.
https://kubernetes.io/docs/concepts/workloads/pods/pod-topology-spread-constraints/
Pod Topology Spread
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: topologyspread
spec:
replicas: 10
selector:
matchLabels:
app: appspread
template:
metadata:
labels:
app: appspread
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/region
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: appspread
containers:
- name: alpha
image: particule/helloworld
ports:
- containerPort: 80
Cette contrainte va indiquer que les pods possédant un label app=appspread
devront être schédulés de manière équilibrée entre les nodes ayant un label
topology.kubernetes.io/region différent. Le champ maxSkew permet de définir
l’écart accepté entre les nodes. Plus le chiffre est bas, plus la répartition
sera équitable.
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
topologyspread-5f7bbcf4c7-5nj4z 1/1 Running 0 13m 100.64.0.10 scw-kosmos-particule-default-ca8e9028f1b745698 <none> <none>
topologyspread-5f7bbcf4c7-7gpcl 1/1 Running 0 13m 100.64.0.11 scw-kosmos-particule-default-ca8e9028f1b745698 <none> <none>
topologyspread-5f7bbcf4c7-8zzwx 1/1 Running 0 13m 100.64.3.5 scw-kosmos-particule-pool-aws-1-8f13ce647e914e <none> <none>
topologyspread-5f7bbcf4c7-dkzp5 1/1 Running 0 13m 100.64.1.8 scw-kosmos-particul-pool-quirky-lederbe-2cc069 <none> <none>
topologyspread-5f7bbcf4c7-f7g2f 1/1 Running 0 13m 100.64.1.9 scw-kosmos-particul-pool-quirky-lederbe-2cc069 <none> <none>
topologyspread-5f7bbcf4c7-lftdr 1/1 Running 0 13m 100.64.0.9 scw-kosmos-particule-default-ca8e9028f1b745698 <none> <none>
topologyspread-5f7bbcf4c7-mzlbn 1/1 Running 0 13m 100.64.3.6 scw-kosmos-particule-pool-aws-1-8f13ce647e914e <none> <none>
topologyspread-5f7bbcf4c7-nrvph 1/1 Running 0 13m 100.64.2.6 scw-kosmos-particule-pool-ovh-1-418092d35df44e <none> <none>
topologyspread-5f7bbcf4c7-xv6lk 1/1 Running 0 13m 100.64.1.7 scw-kosmos-particul-pool-quirky-lederbe-2cc069 <none> <none>
topologyspread-5f7bbcf4c7-z96pn 1/1 Running 0 13m 100.64.2.5 scw-kosmos-particule-pool-ovh-1-418092d35df44e <none> <none>
- 2 pods sur le pool AWS
- 2 pods sur le pool OVH
- 3 pods sur le pool AMS
- 3 pods sur le pool WAW
Si un pod supplémentaire était nécessaire, il serait schédulé sur AWS ou OVH
pour respecter le maxSkew=1.
Conclusion
Encore en beta fermée, Kosmos offre de réelles possibilités en terme de déploiement multi-cloud. Nous manquons encore d’informations sur l’implémentation technique, sur l’intégration avec le reste de l’écosystème Scaleway, mais cela viendra au fur et à mesure. Il nous faut aussi attendre une intégration au provider Terraform pour bénéficier des apports de l’Infra as Code.
Kubernetes Kapsule est et reste gratuit, vous ne payez que les nodes que vous ajoutez à votre cluster. Kosmos est quant à lui facturé ~100€/mois (-50% pendant la beta privée) pour un nombre illimité de nodes externes.
Romain Guichard, CEO & co-founder