Formation Cloud
Concernant ces supports de cours
Supports de cours réalisés par Particule
![]()
- ex Osones/Alterway
- Expertise Cloud Native
- Expertise DevOps
- Nos offres de formations: https://particule.io/trainings/
- Sources : https://github.com/particuleio/formations/
- HTML/PDF : https://particule.io/formations/
Copyright
- Licence : Creative Commons BY-SA 4.0
- Copyright © 2014-2019 alter way Cloud Consulting
- Copyright © 2020 particule.
- Depuis 2020, tous les commits sont la propriété de leurs auteurs respectifs
Introduction
Objectifs de la formation : Tirer avantage du Cloud par les bonnes pratiques
- Comprendre les bonnes pratiques en matière d'infrastructures hébergées dans le Cloud
- Etre capable de discerner ce qui est cloud-compatible et ce qui ne l'est pas
- Comprendre les bonnes pratiques en matière de conception d'applications destinées au Cloud
- Adapter au Cloud ses méthodes d'administration système
- Anticiper l'impact sur les métiers et prévoir les changements dans l'organisation
Des bonnes pratiques : pour quoi faire ?
- Déployer les applications sur n'importe quel cloud
- Utiliser pleinement les services du cloud
- Minimiser le coût et le temps d'intégration des nouveaux équipiers
- Mettre l'application à l'échelle sans remise en cause lourde
- Entrer dans le cercle vertueux des MEP agiles
- Optimiser la facture
Le cloud, vue d'ensemble
Caractéristiques
Fournir un (des) service(s)...
- Self service
- À travers le réseau
- Mutualisation des ressources
- Élasticité rapide
- Mesurabilité
Inspiré de la définition du NIST https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-145.pdf
Self service
- L'utilisateur accède directement au service
- Pas d'intermédiaire humain
- Réponses immédiates
- Catalogue de services permettant leur découverte
À travers le réseau
- L'utilisateur accède au service à travers le réseau
- Le fournisseur du service est distant du consommateur
- Réseau = internet ou pas
- Utilisation de protocoles réseaux standards (typiquement : HTTP)
Mutualisation des ressources
- Un cloud propose ses services à de multiples utilisateurs/organisations (multi-tenant)
- Tenant ou projet : isolation logique des ressources
- Les ressources sont disponibles en grandes quantités (considérées illimitées)
- Le taux d'occupation du cloud n'est pas visible
- La localisation précise des ressources n'est pas visible
Élasticité rapide
- Provisionning et suppression des ressources quasi instantané
- Permet le scaling (passage à l'échelle)
- Possibilité d'automatiser ces actions de scaling
- Virtuellement pas de limite à cette élasticité
Mesurabilité
- L'utilisation des ressources cloud est monitorée par le fournisseur
- Le fournisseur peut gérer son capacity planning et sa facturation à partir de ces informations
- L'utilisateur est ainsi facturé en fonction de son usage précis des ressources
- L'utilisateur peut tirer parti de ces informations
Modèles
On distingue :
- modèles de service : IaaS, PaaS, SaaS
- modèles de déploiement : public, privé, hybride
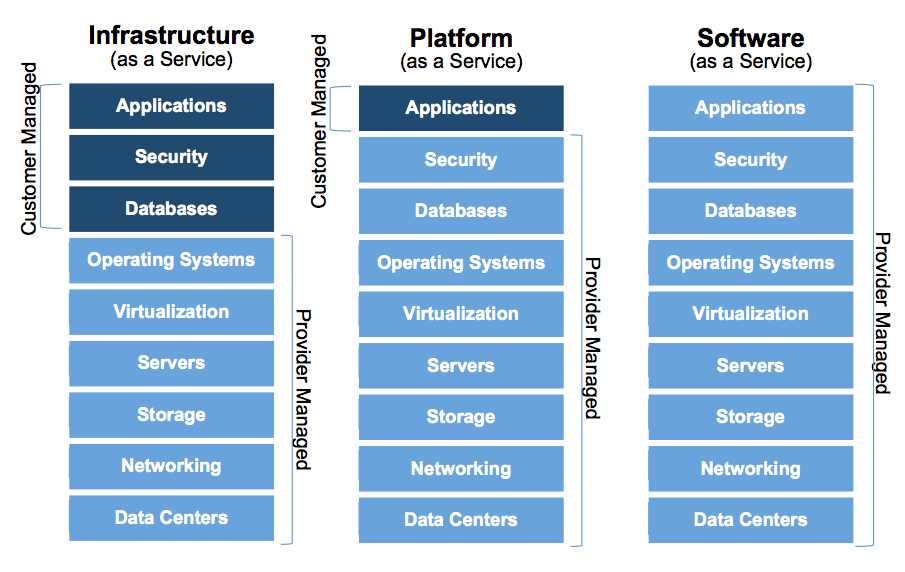
IaaS
- Infrastructure as a Service
- Infrastructure :
- Compute (calcul)
- Storage (stockage)
- Network (réseau)
- Utilisateurs cibles : administrateurs (système, stockage, réseau)
PaaS
- Platform as a Service
- Désigne deux concepts :
- Environnement permettant de développer/déployer une application (spécifique à un langage/framework - exemple : Python/Django)
- Ressources plus haut niveau que l'infrastructure, exemple : BDD
- Utilisateurs cibles : développeurs d'application
SaaS
- Software as a Service
- Utilisateurs cibles : utilisateurs finaux
- Ne pas confondre avec la définition économique du SaaS
Quelquechose as a Service ?
- Load balancing as a Service (Infra)
- Database as a Service (Platform)
- MonApplication as a Service (Software)
- etc.
Les modèles de service en un schéma
Cloud public ou privé ?
À qui s'adresse le cloud ?
- Public : tout le monde, disponible sur internet
- Privé : à une organisation, disponible sur son réseau
Cloud hybride
- Utilisation mixte de multiples clouds privés et/ou publics
- Concept séduisant mais mise en œuvre a priori difficile
- Certains cas d'usages s'y prêtent très bien
- Intégration continue (CI)
- Motivations
- Éviter le lock-in
- Débordement (cloud bursting)
L'instant virtualisation
Mise au point.
- La virtualisation est une technologie permettant d'implémenter la fonction compute
- Un cloud fournissant du compute peut utiliser la virtualisation
- Mais peut également utiliser :
- Du bare-metal
- Des containers (système)
Les APIs, la clé du cloud
- Rappel : API pour Application Programming Interface
- Au sens logiciel : Interface permettant à un logiciel d’utiliser une bibliothèque
- Au sens cloud : Interface permettant à un logiciel d’utiliser un service (XaaS)
- Interface de programmation (via le réseau, souvent HTTP)
- Frontière explicite entre le fournisseur (provider) et l'utilisateur (user)
- Définit la manière dont l'utilisateur communique avec le cloud pour gérer ses ressources
- Gérer : CRUD (Create, Read, Update, Delete)
API REST
- Une ressource == une URI (Uniform Resource Identifier)
- Utilisation des verbes HTTP pour caractériser les opérations (CRUD)
- GET
- POST
- PUT
- DELETE
- Utilisation des codes de retour HTTP
- Représentation des ressources dans le corps des réponses HTTP
REST - Exemples
GET http://endpoint/volumes/
GET http://endpoint/volumes/?size=10
POST http://endpoint/volumes/
DELETE http://endpoint/volumes/xyzExemple concret
GET /v2.0/networks/d32019d3-bc6e-4319-9c1d-6722fc136a22
{
"network":{
"status":"ACTIVE",
"subnets":[ "54d6f61d-db07-451c-9ab3-b9609b6b6f0b" ],
"name":"private-network",
"provider:physical_network":null,
"admin_state_up":true,
"tenant_id":"4fd44f30292945e481c7b8a0c8908869",
"provider:network_type":"local",
"router:external":true,
"shared":true,
"id":"d32019d3-bc6e-4319-9c1d-6722fc136a22",
"provider:segmentation_id":null
}
}Pourquoi le cloud ? côté économique
- Appréhender les ressources IT comme des services “fournisseur”
- Faire glisser le budget “investissement” (Capex) vers le budget “fonctionnement” (Opex)
- Réduire les coûts en mutualisant les ressources, et éventuellement avec des économies d'échelle
- Réduire les délais
- Aligner les coûts sur la consommation réelle des ressources
Pourquoi le cloud ? côté technique
- Abstraire les couches basses (serveur, réseau, OS, stockage)
- S’affranchir de l’administration technique des ressources et services (BDD, pare-feux, load-balancing, etc.)
- Concevoir des infrastructures scalables à la volée
- Agir sur les ressources via des lignes de code et gérer les infrastructures “comme du code”
Le marché
Amazon Web Services (AWS), le leader

- Lancement en 2006
- À l'origine : services web "e-commerce" pour développeurs
- Puis : d'autres services pour développeurs
- Et enfin : services d'infrastructure
- Récemment, SaaS
Alternatives IaaS publics à AWS
- Google Cloud Platform
- Microsoft Azure
- DigitalOcean
- Alibaba Cloud
- En France :
- Scaleway
- OVH
- Outscale
- Ikoula
Faire du IaaS privé
- OpenStack
- CloudStack
- Eucalyptus
- OpenNebula
OpenStack en quelques mots

- Naissance en 2010
- Fondation OpenStack depuis 2012...
- ...rebaptisée Open Infrastructure Foundation en 2020 (https://openinfra.dev/)
- Écrit en Python et distribué sous licence Apache 2.0
- Soutien très large de l'industrie et contributions variées
Exemples de PaaS public
- Amazon Elastic Beanstalk (https://aws.amazon.com/fr/elasticbeanstalk)
- Google App Engine (https://cloud.google.com/appengine)
- Heroku (https://www.heroku.com)
Solutions de PaaS privé
- Cloud Foundry, Fondation (https://www.cloudfoundry.org)
- OKD, Red Hat (https://www.okd.io)
- Solum, OpenStack (https://wiki.openstack.org/wiki/Solum)
Les concepts Infrastructure as a Service
La base
- Infrastructure :
- Compute
- Storage
- Network
Ressources compute
- Instance
- Image
- Flavor (gabarit)
- Paire de clé (SSH)
Instance
- Dédiée au compute
- Durée de vie typiquement courte, à considérer comme éphémère
- Ne doit pas stocker de données persistantes
- Disque racine non persistant
- Basée sur une image
Image cloud
- Image disque contenant un OS déjà installé
- Instanciable à l'infini
- Sachant parler à l'API de metadata
API ... de metadata
http://169.254.169.254- Accessible depuis l'instance
- Fournit des informations relatives à l'instance
- Expose les userdata
- L'outil
cloud-initpermet d'exploiter cette API
Flavor (gabarit)
- Instance type chez AWS
- Définit un modèle d’instance en termes de CPU, RAM, disque (racine), disque éphémère
- Le disque éphémère a, comme le disque racine, l’avantage d’être souvent local donc rapide
Paire de clé
- Clé publique + clé privée SSH
- Le cloud manipule et stocke la clé publique
- Cette clé publique est utilisée pour donner un accès SSH aux instances
Ressources réseau 1/2
- Réseau L2
- Port réseau
- Réseau L3
- Routeur
- IP flottante
- Groupe de sécurité
Ressources réseau 2/2
- Load Balancing as a Service
- VPN as a Service
- Firewall as a Service
Ressources stockage
Le cloud fournit deux types de stockage
- Block
- Objet
Stockage block
- Volumes attachables à une instance
- Accès à des raw devices type /dev/vdb
- Possibilité d’utiliser n’importe quel système de fichiers
- Possibilité d'utiliser du LVM, du chiffrement, etc.
- Compatible avec toutes les applications existantes
- Nécessite de provisionner l'espace en définissant la taille du volume
Du stockage partagé ?
- Le stockage block n’est pas une solution de stockage partagé comme NFS
- NFS se situe à une couche plus haute : système de fichiers
- Un volume est a priori connecté à une seule machine
"Boot from volume"
Démarrer une instance avec un disque racine sur un volume
- Persistance des données du disque racine
- Se rapproche du serveur classique
Stockage objet
- API : faire du CRUD sur les données
- Pousser et retirer des objets dans un container/bucket
- Pas de hiérarchie, pas de répertoires, pas de système de fichiers
- Accès lecture/écriture uniquement par les APIs
- Pas de provisioning nécessaire
- L’application doit être conçue pour tirer parti du stockage objet
Orchestration
- Orchestrer la création et la gestion des ressources dans le cloud
- Définition de l'architecture dans un template
- Les ressources créées à partir du template forment la stack
- Il existe également des outils d'orchestration (plutôt que des services)
Bonnes pratiques d'utilisation
Pourquoi des bonnes pratiques ?
Deux approches :
- Ne pas évoluer
- Risquer de ne pas répondre aux attentes
- Se contenter d'un cas d'usage test & dev
- Adapter ses pratiques au cloud pour en tirer parti pleinement
Haute disponibilité (HA)
- Le control plane (les APIs) du cloud est HA
- Les ressources provisionnées ne le sont pas forcément
Pet vs Cattle
Comment considérer ses instances ?
- Pet
- Cattle
Infrastructure as Code
Avec du code
- Provisionner les ressources d'infrastructure
- Configurer les dites ressources, notamment les instances
Le métier évolue : Infrastructure Developer
Scaling, passage à l'échelle
- Scale out plutôt que Scale up
- Scale out : passage à l'échelle horizontal
- Scale up : passage à l'échelle vertical
- Auto-scaling
- Géré par le cloud
- Géré par un composant extérieur
Applications cloud ready
- Stockent leurs données au bon endroit
- Sont architecturées pour tolérer les pannes
- Etc.
Derrière le cloud
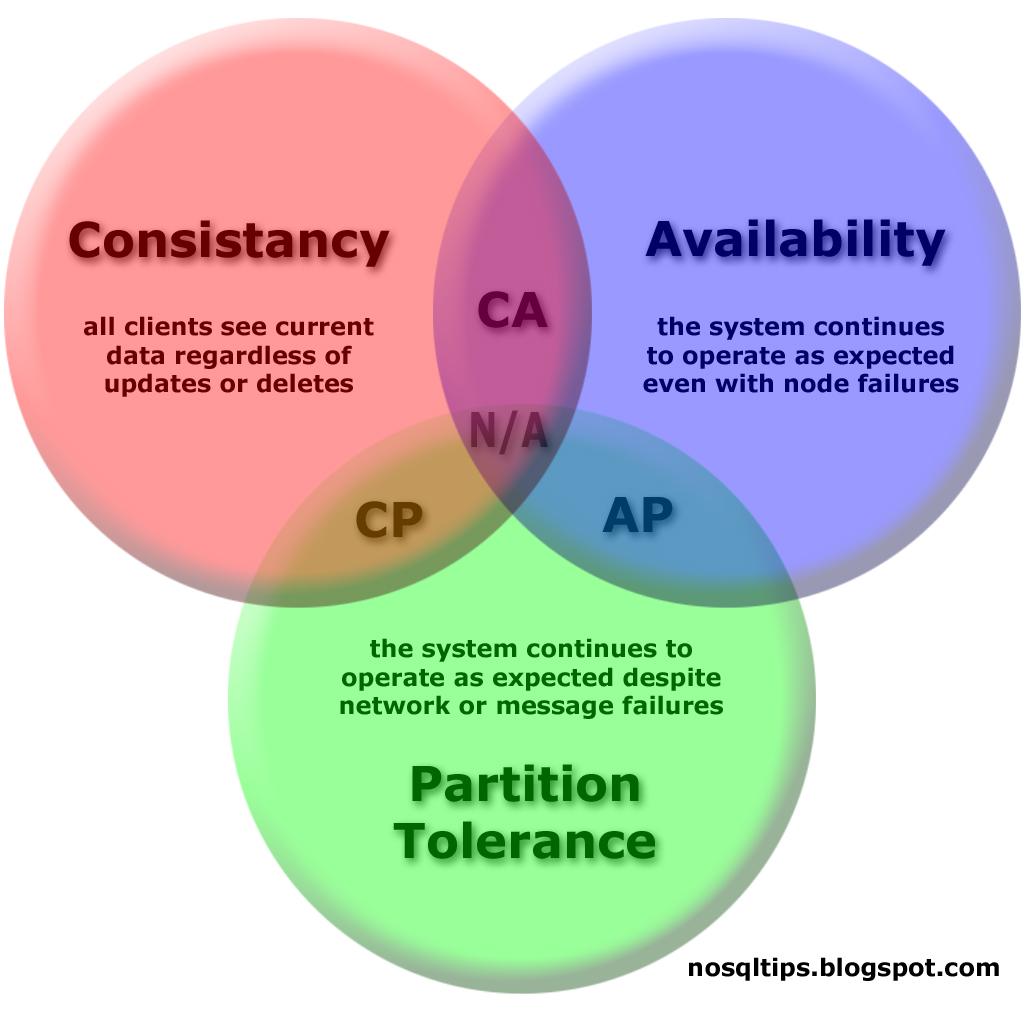
Implémentation du stockage : (Software Defined Storage) SDS
Attention : ne pas confondre avec le sujet block vs objet
- Utilisation de commodity hardware
- Pas de RAID matériel
- Le logiciel est responsable de garantir les données
- Les pannes matérielles sont prises en compte et gérées
- Le projet Ceph et le composant OpenStack Swift implémentent du SDS
Voir aussi Scality, OpenIO, OpenSDS,...
SDS - Théorème CAP
Concevoir une application pour le Cloud
La référence : les 12 facteurs
“The Twelve-Factor App” https://12factor.net/fr/
- Publié par Heroku https://www.heroku.com/what/
- Ecrit par des développeurs, des architectes et des ops
- Recueil de préconisations techniques issues d'expériences terrain
- Destiné aux développeurs et aux personnes en charge du déploiement et du Run
- Applicable quel que soit le langage de programmation
Les 12 facteurs en détails (1/2)
- Base de code : unique, suivie dans un VCS, plusieurs déploiements
- Dépendances : les isoler et les déclarer explicitement
- Configuration : différencier les environnements via les variables de conf.
- Services externes : les traiter comme des ressources attachées
- Build, release, run : séparer strictement les étapes d’assemblage et d’exécution
- Processus : exécuter l’application comme un ou plusieurs processus sans état
Les 12 facteurs en détails (2/2)
- Ports : exporter les services de l'application via des ports TCP
- Mise à l'échelle : utiliser le modèle de processus
- Jetable : maximisez la robustesse avec des démarrages rapides et des arrêts en douceur
- Parité dev/prod : gardez les différents environnements aussi proches que possible
- Logs : les traiter comme des flux d’évènements
- Processus d’administration et de maintenance : les lancer comme des processus one-off
Penser son application “cloud ready” 1/3
- Une base de code unique suivie dans un VCS (Git,...)
- Une configuration par environnement
- Architecture distribuée plutôt que monolithique
- Facilite le passage à l’échelle
- Limite les domaines de failure
- Couplage faible entre les composants
Penser son application “cloud ready” 2/3
- Bus de messages pour les communications inter-composants
- Stateless : permet de multiplier les routes d’accès à l’application
- Dynamicité : l’application doit s’adapter à son environnement et se reconfigurer lorsque nécessaire
- Permettre le déploiement et l’exploitation par des outils d’automatisation
Penser son application “cloud ready” 3/3
- Limiter autant que possible les dépendances à du matériel ou du logiciel spécifique qui pourrait ne pas fonctionner dans un cloud
- Tolérance aux pannes (fault tolerance) intégrée
- Ne pas stocker les données en local, mais plutôt :
- Base de données
- Stockage bloc
- Stockage objet
- Utiliser des outils de journalisation standards
Modularité
- Philosophie Unix (Keep It Simple Stupid)
- Multiples composants de taille raisonnable
- Couplage faible et interface documentée
Passage à l’échelle
- Pets versus Cattle
- Vertical vs Horizontal
- Scale up/down vs Scale out/in
- Plusieurs petites instances plutôt qu’une seule grosse
Stateful vs stateless
- Beaucoup de stateful dans les applications legacy
- Nécessite de partager l’information d’état lorsque plusieurs workers
- Le stateless élimine cette contrainte
Tolérance aux pannes
- Les APIs du cloud sont hautement disponibles
- Le cloud ne garantit pas la haute disponibilté de l'application
- L’application prend en charge sa propre tolérance aux pannes
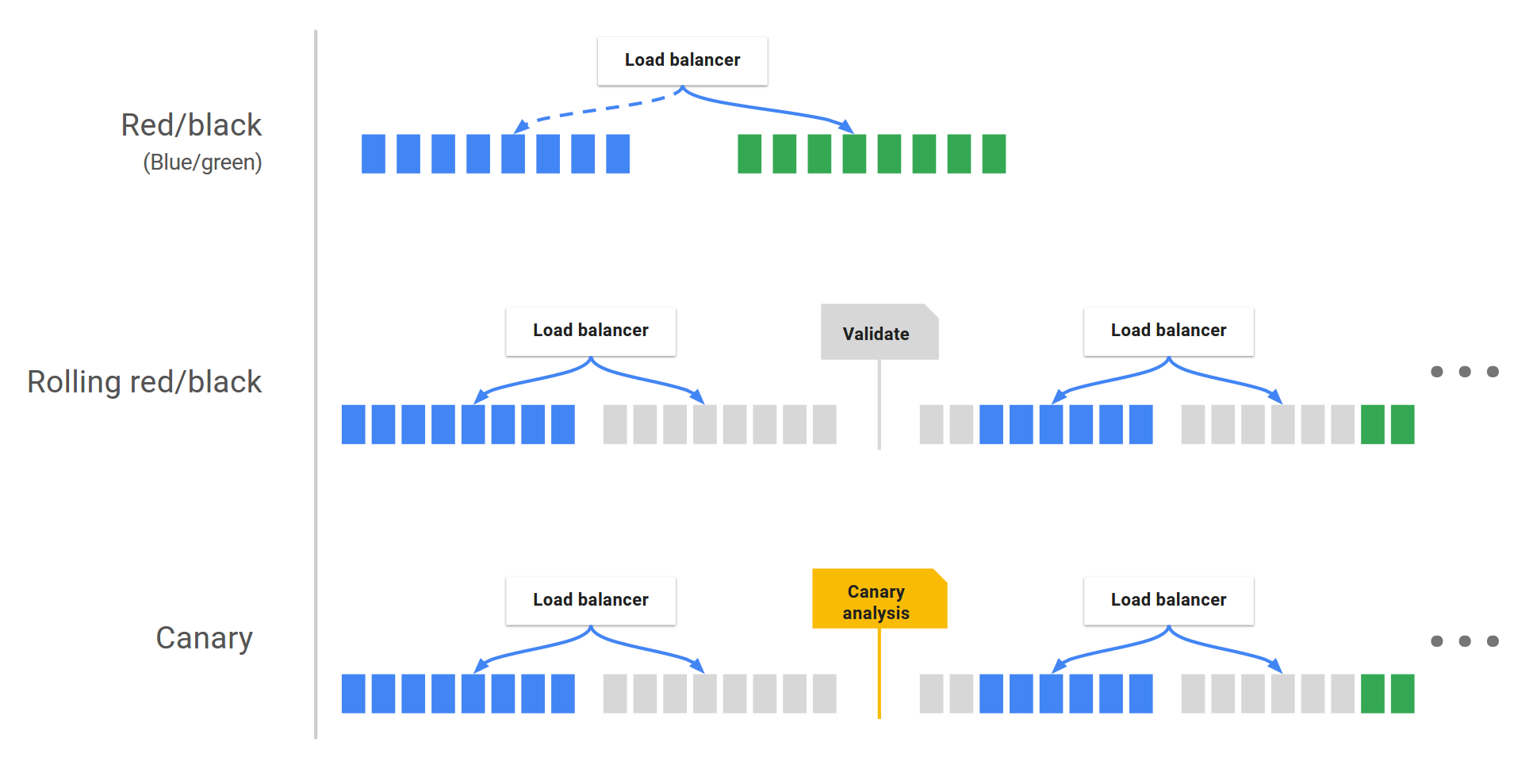
Modèles de déploiement
- Blue-Green (attention aux quotas)
- Rolling
- Canary
Stockage des données
- Base de données relationnelle
- Base de données NoSQL
- Stockage bloc
- Stockage objet
- Stockage éphémère
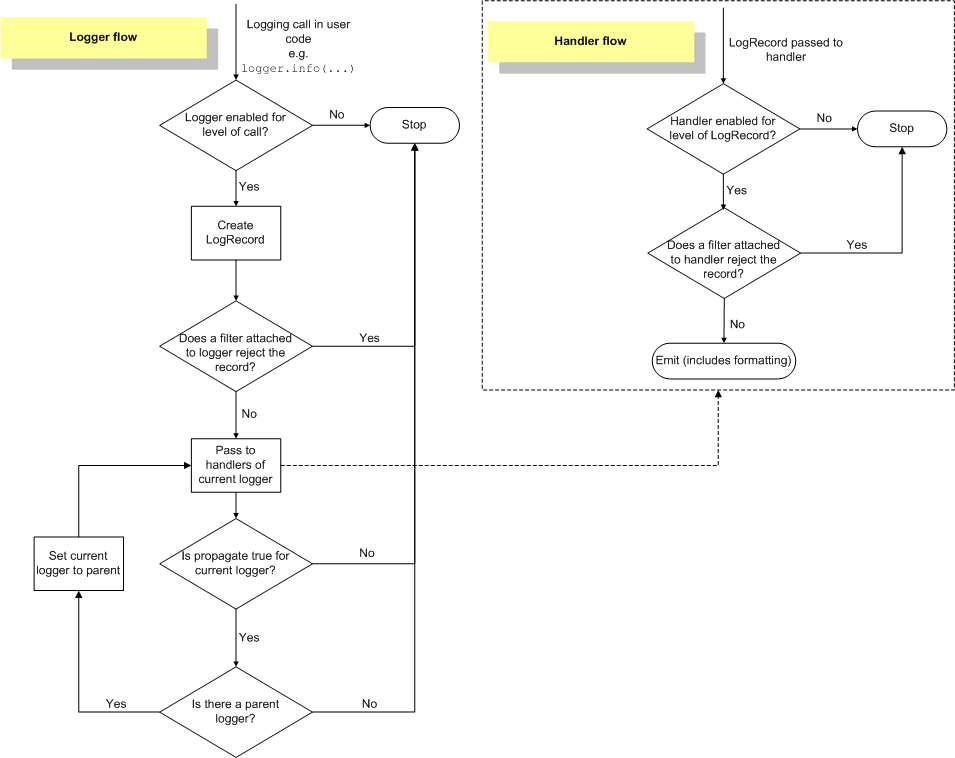
Gestion des logs
- Rester "applicatif"
- Enrichir les logs
- Ne pas présupposer le backend de traitement -> dans la conf
Exemple en python
appLog.conf:
[logger_myapp]
qualname=mycompany.myapp
level=INFO
handlers=console
propagate=0app.py:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import logging
log = logging.getLogger('mycompany.myapp.maintask')
log.info('Main worker started')2018-12-24 22:20:02 INFO appuser Main worker startedLogging flow
Migration des applications legacy
- Rappel des enjeux
- Migrer ou non : critères de décision
Concevoir une infra pour le cloud
L'infra au service de son application
- Souplesse
- Résilience
- Performance
- Opérabilité
Une infra, ça évolue !
- Dimensionnement des clusters
- Maintenance des O.S. « guest » et du middleware
- Règles SSI : segmentation réseau, filtrage de flux, proxys, bastions, annuaires
- Ajout de nouveaux services
Mécaniser, automatiser, industrialiser
- Le niveau d'anxiété des comités face à la décision de déployer est inversement proportionnelle à la fréquence des MEP => cercle vicieux
- (re)Construire, faire évoluer et maintenir les infras hébergées dans le cloud
- Reconstruction totale ou partielle à la demande
- Reproductibilité
- C'est Automagique !
Automatisation
- Mécaniser la gestion de l’infrastructure : indispensable
- Automatiser la gestion de l’infrastructure : un plus !
- Création des ressources
- Configuration des ressources
Infrastructure as Code
- L'infra s'appréhende comme du code
- Travailler comme un développeur
- Décrire son infrastructure sous forme de code (Heat, Terraform)
- Suivre les changements dans un VCS (git), qui devient la référence
- Mettre en oeuvre un système d'intégration et de déploiement continus (CI/CD)
Approche de Heat
- Un service <-> une API OpenStack
- Notions de stack et description YAML
- Précautions d'usage (stack update)
- Cas d'usage type
Exemple Heat
---
heat_template_version: 2018-08-31
description: A single nova instance
parameters:
flavorName:
type: string
resources:
instance:
type: OS::Nova::Server
properties:
name: MonInstance
image: debianStretchOfTheDay
flavor: {get_param: flavorName}
key_name: MaCleSSH
outputs:
instanceId:
value: {get_resource: instance}Approche de Terraform
- L'aspect "cloud agnostique"
- Le DSL de Terraform
- L'exigence Infra as Code (terraform.tfstate)
- Cas d'usage type
Exemple Terraform
# A single nova instance
# Configure the OpenStack Provider
provider "openstack" {
user_name = "MyName"
tenant_name = "MyTenant"
password = "MyPwd"
auth_url = "http://myauthurl:5000/v2.0"
region = "RegionOne"
}
resource "openstack_compute_instance_v2" "MonInstance" {
name = "MonInstance"
count = "1"
image_name = ""
flavor_name = "${var.flavor}"
key_pair = "MaCleSSh"
}Agilité et CI/CD appliquées à l'infra
- Style de code
- Vérification de la syntaxe
- Tests unitaires
- Tests d'intégration
- Tests fonctionnels de bout en bout
Tolérance aux pannes
- Notion de résilience
- Load balancers
- Floating IPs
- Groupes de serveurs stateless
- Healthchecks
Mise à l'échelle / élasticité horizontale
- Groupe d’instances similaires, autoscaling group
- Nombre d’instances variable
- Scaling automatique en fonction de métriques
Supervision
- Prendre en compte le cycle de vie des instances : DOWN != ALERT
- Monitorer les services plutôt que les serveurs
- Oublier les adresses IP ! Exposer un web service
- Prévoir un healthcheck fonctionnel (use case "métier")
Backup, PCA
- Infrastructure : être capable de reconstruire n'importe quel environnement à tout moment
- Données (de l'application, logs) : utiliser les modes de stockage bloc (volumes) et objet (dossiers)
Gérer ses images
- Utilisation d’images génériques et personnalisation à l’instanciation (cloud-init)
- Création d’images offline :
- from scratch : diskimage-builder (TripleO)
- from scratch avec des outils spécifiques aux distributions (
openstack-debian-imagespour Debian) - modifiées avec libguestfs, virt-builder, virt-sysprep
- Création d’images via une instance :
- automatisation possible avec Packer, Terraform, le CLI ou les API du IaaS
- Golden images
Adapter le Métier et l'Organisation
Impacts sur les métiers
- l'Architecte
- l'Intégrateur
- l'Administrateur système
- l'Administrateur de base de données
Retours d'expériences
- Convergence de métiers existants : architecte // intégrateur
- doivent se comprendre et collaborer
- Apparition d'un nouveau métier : développeur d'infra
- Pilotage projet : doit être traité comme un développeur d'application en termes de budget, de compétences requises et d'organisation.
Repenser l'organisation
- Adapter l'organisation sans tout chambouler
- Une dose d'agilité
- Amélioration continue et approche itérative
Conclusion best practices
Le cocktail gagnant
Nécessité d'adapter ses pratiques et ses compétences pour tirer tous les bénéfices attendus d'une migration vers le Cloud. Sinon, risque de ne pas répondre aux attentes et/ou de se contenter d'un cas d'usage « test & dev ».
Application cloud ready (https://12factor.net)
Infrastructure as Code
- Passage à l'échelle (scaling)
- pets vs cattle
- horizontal plutôt que vertical
L'application prend elle-même en charge sa haute disponibilté
Approche et organisation DevOps
Les bénéfices
Infrastructures programmables → + souples que les schémas traditionnels et les workflows associés
MEP mécanisées et reproductibles → dédramatisées, donc + fréquentes, donc dédramatisées => cercle vertueux
Approche « zero admin » des serveurs en production → - d 'erreurs humaines, + de disponibilité des applications
Applications outillées : → exploitabilité industrielle prise en compte dès les phases poc/pilote.
Catalogue de composants → des équipes de développement qui créent + de valeur « métier »
Comment implémenter un service de Compute