Formation OpenStack
Concernant ces supports de cours
Supports de cours réalisés par Particule
![]()
- ex Osones/Alterway
- Expertise Cloud Native
- Expertise DevOps
- Nos offres de formations: https://particule.io/trainings/
- Sources : https://github.com/particuleio/formations/
- HTML/PDF : https://particule.io/formations/
Copyright
- Licence : Creative Commons BY-SA 4.0
- Copyright © 2014-2019 alter way Cloud Consulting
- Copyright © 2020 particule.
- Depuis 2020, tous les commits sont la propriété de leurs auteurs respectifs
Introduction
Objectifs de la formation : Cloud
- Comprendre les principes du cloud et son intérêt
- Connaitre le vocabulaire inhérent au cloud
- Avoir une vue d’ensemble sur les solutions existantes en cloud public et privé
- Posséder les clés pour tirer parti au mieux du IaaS
- Pouvoir déterminer ce qui est compatible avec la philosophie cloud ou pas
- Adapter ses méthodes d’administration système et de développement à un environnement cloud
Objectifs de la formation : OpenStack
- Connaitre le fonctionnement du projet OpenStack et ses possibilités
- Comprendre le fonctionnement de chacun des composants d’OpenStack
- Pouvoir faire les bons choix de configuration
- Savoir déployer manuellement un cloud OpenStack pour fournir du IaaS
- Connaitre les bonnes pratiques de déploiement d’OpenStack
- Être capable de déterminer l’origine d’une erreur dans OpenStack
- Savoir réagir face à un bug
Pré-requis de la formation
- Compétences d’administration système Linux
- Gestion des paquets
- Manipulation de fichiers de configuration/services
- LVM et systèmes de fichiers
- Notions :
- Virtualisation : KVM, libvirt
- Réseau : iptables, namespaces
- SQL
- Optionnel:
- À l’aise dans un environnement Python
Le cloud, vue d'ensemble
Caractéristiques
Fournir un (des) service(s)...
- Self service
- À travers le réseau
- Mutualisation des ressources
- Élasticité rapide
- Mesurabilité
Inspiré de la définition du NIST https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-145.pdf
Self service
- L'utilisateur accède directement au service
- Pas d'intermédiaire humain
- Réponses immédiates
- Catalogue de services permettant leur découverte
À travers le réseau
- L'utilisateur accède au service à travers le réseau
- Le fournisseur du service est distant du consommateur
- Réseau = internet ou pas
- Utilisation de protocoles réseaux standards (typiquement : HTTP)
Mutualisation des ressources
- Un cloud propose ses services à de multiples utilisateurs/organisations (multi-tenant)
- Tenant ou projet : isolation logique des ressources
- Les ressources sont disponibles en grandes quantités (considérées illimitées)
- Le taux d'occupation du cloud n'est pas visible
- La localisation précise des ressources n'est pas visible
Élasticité rapide
- Provisionning et suppression des ressources quasi instantané
- Permet le scaling (passage à l'échelle)
- Possibilité d'automatiser ces actions de scaling
- Virtuellement pas de limite à cette élasticité
Mesurabilité
- L'utilisation des ressources cloud est monitorée par le fournisseur
- Le fournisseur peut gérer son capacity planning et sa facturation à partir de ces informations
- L'utilisateur est ainsi facturé en fonction de son usage précis des ressources
- L'utilisateur peut tirer parti de ces informations
Modèles
On distingue :
- modèles de service : IaaS, PaaS, SaaS
- modèles de déploiement : public, privé, hybride
IaaS
- Infrastructure as a Service
- Infrastructure :
- Compute (calcul)
- Storage (stockage)
- Network (réseau)
- Utilisateurs cibles : administrateurs (système, stockage, réseau)
PaaS
- Platform as a Service
- Désigne deux concepts :
- Environnement permettant de développer/déployer une application (spécifique à un langage/framework - exemple : Python/Django)
- Ressources plus haut niveau que l'infrastructure, exemple : BDD
- Utilisateurs cibles : développeurs d'application
SaaS
- Software as a Service
- Utilisateurs cibles : utilisateurs finaux
- Ne pas confondre avec la définition économique du SaaS
Quelquechose as a Service ?
- Load balancing as a Service (Infra)
- Database as a Service (Platform)
- MonApplication as a Service (Software)
- etc.
Les modèles de service en un schéma
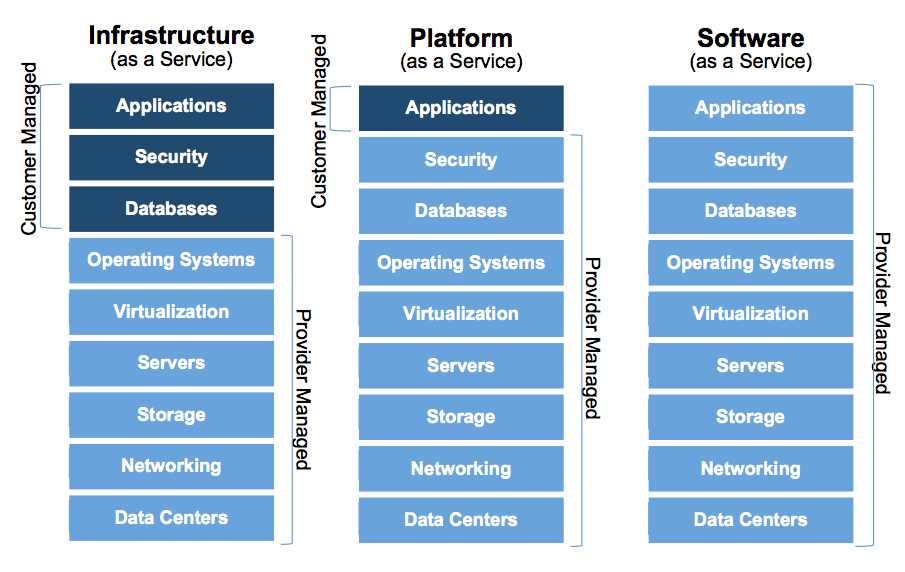
Cloud public ou privé ?
À qui s'adresse le cloud ?
- Public : tout le monde, disponible sur internet
- Privé : à une organisation, disponible sur son réseau
Cloud hybride
- Utilisation mixte de multiples clouds privés et/ou publics
- Concept séduisant mais mise en œuvre a priori difficile
- Certains cas d'usages s'y prêtent très bien
- Intégration continue (CI)
- Motivations
- Éviter le lock-in
- Débordement (cloud bursting)
L'instant virtualisation
Mise au point.
- La virtualisation est une technologie permettant d'implémenter la fonction compute
- Un cloud fournissant du compute peut utiliser la virtualisation
- Mais peut également utiliser :
- Du bare-metal
- Des containers (système)
Les APIs, la clé du cloud
- Rappel : API pour Application Programming Interface
- Au sens logiciel : Interface permettant à un logiciel d’utiliser une bibliothèque
- Au sens cloud : Interface permettant à un logiciel d’utiliser un service (XaaS)
- Interface de programmation (via le réseau, souvent HTTP)
- Frontière explicite entre le fournisseur (provider) et l'utilisateur (user)
- Définit la manière dont l'utilisateur communique avec le cloud pour gérer ses ressources
- Gérer : CRUD (Create, Read, Update, Delete)
API REST
- Une ressource == une URI (Uniform Resource Identifier)
- Utilisation des verbes HTTP pour caractériser les opérations (CRUD)
- GET
- POST
- PUT
- DELETE
- Utilisation des codes de retour HTTP
- Représentation des ressources dans le corps des réponses HTTP
REST - Exemples
GET http://endpoint/volumes/
GET http://endpoint/volumes/?size=10
POST http://endpoint/volumes/
DELETE http://endpoint/volumes/xyzExemple concret
GET /v2.0/networks/d32019d3-bc6e-4319-9c1d-6722fc136a22
{
"network":{
"status":"ACTIVE",
"subnets":[ "54d6f61d-db07-451c-9ab3-b9609b6b6f0b" ],
"name":"private-network",
"provider:physical_network":null,
"admin_state_up":true,
"tenant_id":"4fd44f30292945e481c7b8a0c8908869",
"provider:network_type":"local",
"router:external":true,
"shared":true,
"id":"d32019d3-bc6e-4319-9c1d-6722fc136a22",
"provider:segmentation_id":null
}
}Pourquoi le cloud ? côté économique
- Appréhender les ressources IT comme des services “fournisseur”
- Faire glisser le budget “investissement” (Capex) vers le budget “fonctionnement” (Opex)
- Réduire les coûts en mutualisant les ressources, et éventuellement avec des économies d'échelle
- Réduire les délais
- Aligner les coûts sur la consommation réelle des ressources
Pourquoi le cloud ? côté technique
- Abstraire les couches basses (serveur, réseau, OS, stockage)
- S’affranchir de l’administration technique des ressources et services (BDD, pare-feux, load-balancing, etc.)
- Concevoir des infrastructures scalables à la volée
- Agir sur les ressources via des lignes de code et gérer les infrastructures “comme du code”
Le marché
Amazon Web Services (AWS), le leader

- Lancement en 2006
- À l'origine : services web "e-commerce" pour développeurs
- Puis : d'autres services pour développeurs
- Et enfin : services d'infrastructure
- Récemment, SaaS
Alternatives IaaS publics à AWS
- Google Cloud Platform
- Microsoft Azure
- DigitalOcean
- Alibaba Cloud
- En France :
- Scaleway
- OVH
- Outscale
- Ikoula
Faire du IaaS privé
- OpenStack
- CloudStack
- Eucalyptus
- OpenNebula
OpenStack en quelques mots

- Naissance en 2010
- Fondation OpenStack depuis 2012...
- ...rebaptisée Open Infrastructure Foundation en 2020 (https://openinfra.dev/)
- Écrit en Python et distribué sous licence Apache 2.0
- Soutien très large de l'industrie et contributions variées
Exemples de PaaS public
- Amazon Elastic Beanstalk (https://aws.amazon.com/fr/elasticbeanstalk)
- Google App Engine (https://cloud.google.com/appengine)
- Heroku (https://www.heroku.com)
Solutions de PaaS privé
- Cloud Foundry, Fondation (https://www.cloudfoundry.org)
- OKD, Red Hat (https://www.okd.io)
- Solum, OpenStack (https://wiki.openstack.org/wiki/Solum)
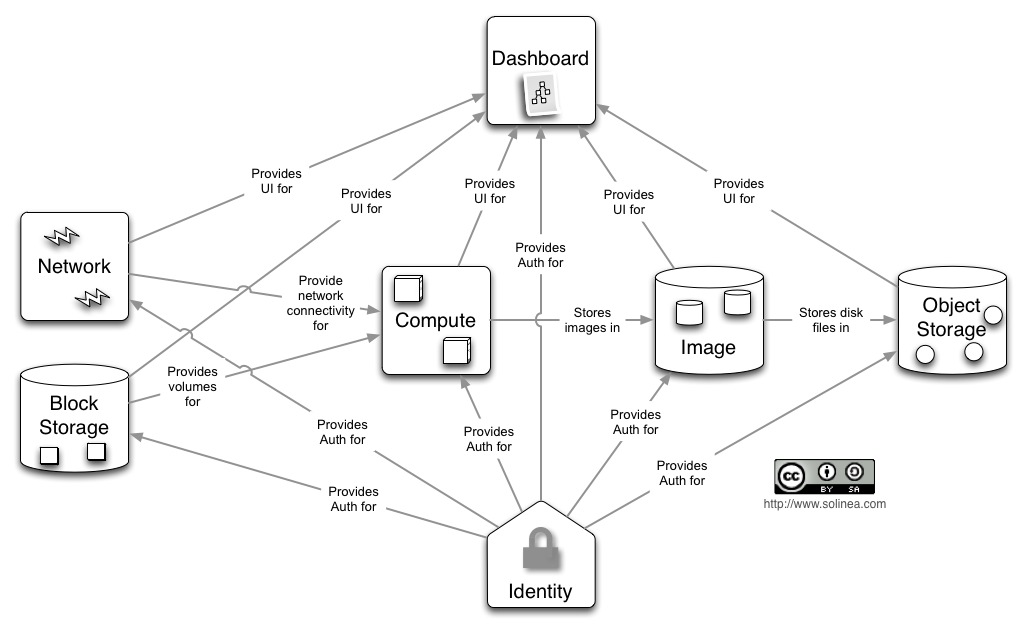
Les concepts Infrastructure as a Service
La base
- Infrastructure :
- Compute
- Storage
- Network
Ressources compute
- Instance
- Image
- Flavor (gabarit)
- Paire de clé (SSH)
Instance
- Dédiée au compute
- Durée de vie typiquement courte, à considérer comme éphémère
- Ne doit pas stocker de données persistantes
- Disque racine non persistant
- Basée sur une image
Image cloud
- Image disque contenant un OS déjà installé
- Instanciable à l'infini
- Sachant parler à l'API de metadata
API ... de metadata
http://169.254.169.254- Accessible depuis l'instance
- Fournit des informations relatives à l'instance
- Expose les userdata
- L'outil
cloud-initpermet d'exploiter cette API
Flavor (gabarit)
- Instance type chez AWS
- Définit un modèle d’instance en termes de CPU, RAM, disque (racine), disque éphémère
- Le disque éphémère a, comme le disque racine, l’avantage d’être souvent local donc rapide
Paire de clé
- Clé publique + clé privée SSH
- Le cloud manipule et stocke la clé publique
- Cette clé publique est utilisée pour donner un accès SSH aux instances
Ressources réseau 1/2
- Réseau L2
- Port réseau
- Réseau L3
- Routeur
- IP flottante
- Groupe de sécurité
Ressources réseau 2/2
- Load Balancing as a Service
- VPN as a Service
- Firewall as a Service
Ressources stockage
Le cloud fournit deux types de stockage
- Block
- Objet
Stockage block
- Volumes attachables à une instance
- Accès à des raw devices type /dev/vdb
- Possibilité d’utiliser n’importe quel système de fichiers
- Possibilité d'utiliser du LVM, du chiffrement, etc.
- Compatible avec toutes les applications existantes
- Nécessite de provisionner l'espace en définissant la taille du volume
Du stockage partagé ?
- Le stockage block n’est pas une solution de stockage partagé comme NFS
- NFS se situe à une couche plus haute : système de fichiers
- Un volume est a priori connecté à une seule machine
"Boot from volume"
Démarrer une instance avec un disque racine sur un volume
- Persistance des données du disque racine
- Se rapproche du serveur classique
Stockage objet
- API : faire du CRUD sur les données
- Pousser et retirer des objets dans un container/bucket
- Pas de hiérarchie, pas de répertoires, pas de système de fichiers
- Accès lecture/écriture uniquement par les APIs
- Pas de provisioning nécessaire
- L’application doit être conçue pour tirer parti du stockage objet
Orchestration
- Orchestrer la création et la gestion des ressources dans le cloud
- Définition de l'architecture dans un template
- Les ressources créées à partir du template forment la stack
- Il existe également des outils d'orchestration (plutôt que des services)
Bonnes pratiques d'utilisation
Pourquoi des bonnes pratiques ?
Deux approches :
- Ne pas évoluer
- Risquer de ne pas répondre aux attentes
- Se contenter d'un cas d'usage test & dev
- Adapter ses pratiques au cloud pour en tirer parti pleinement
Haute disponibilité (HA)
- Le control plane (les APIs) du cloud est HA
- Les ressources provisionnées ne le sont pas forcément
Pet vs Cattle
Comment considérer ses instances ?
- Pet
- Cattle
Infrastructure as Code
Avec du code
- Provisionner les ressources d'infrastructure
- Configurer les dites ressources, notamment les instances
Le métier évolue : Infrastructure Developer
Scaling, passage à l'échelle
- Scale out plutôt que Scale up
- Scale out : passage à l'échelle horizontal
- Scale up : passage à l'échelle vertical
- Auto-scaling
- Géré par le cloud
- Géré par un composant extérieur
Applications cloud ready
- Stockent leurs données au bon endroit
- Sont architecturées pour tolérer les pannes
- Etc.
Derrière le cloud
Implémentation du stockage : (Software Defined Storage) SDS
Attention : ne pas confondre avec le sujet block vs objet
- Utilisation de commodity hardware
- Pas de RAID matériel
- Le logiciel est responsable de garantir les données
- Les pannes matérielles sont prises en compte et gérées
- Le projet Ceph et le composant OpenStack Swift implémentent du SDS
Voir aussi Scality, OpenIO, OpenSDS,...
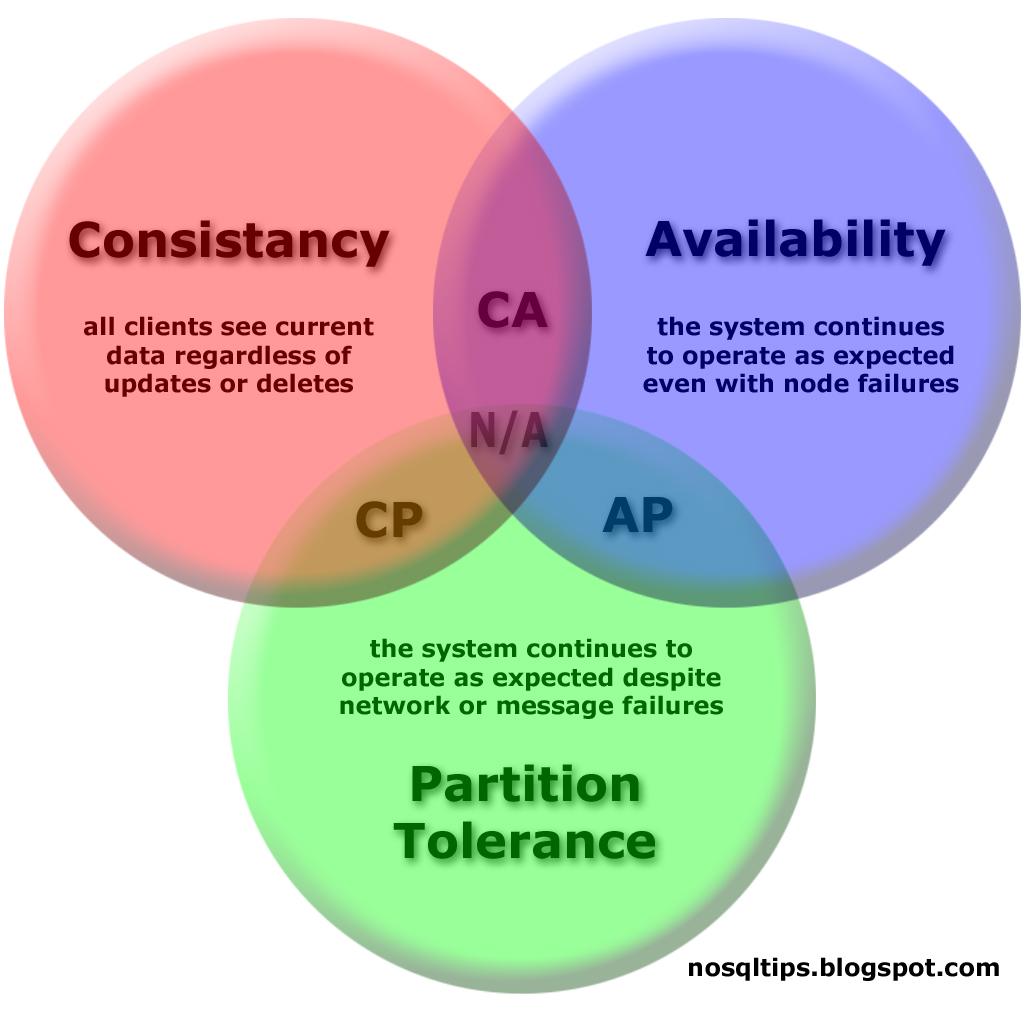
SDS - Théorème CAP
OpenStack : le projet
Vue haut niveau (1/2)
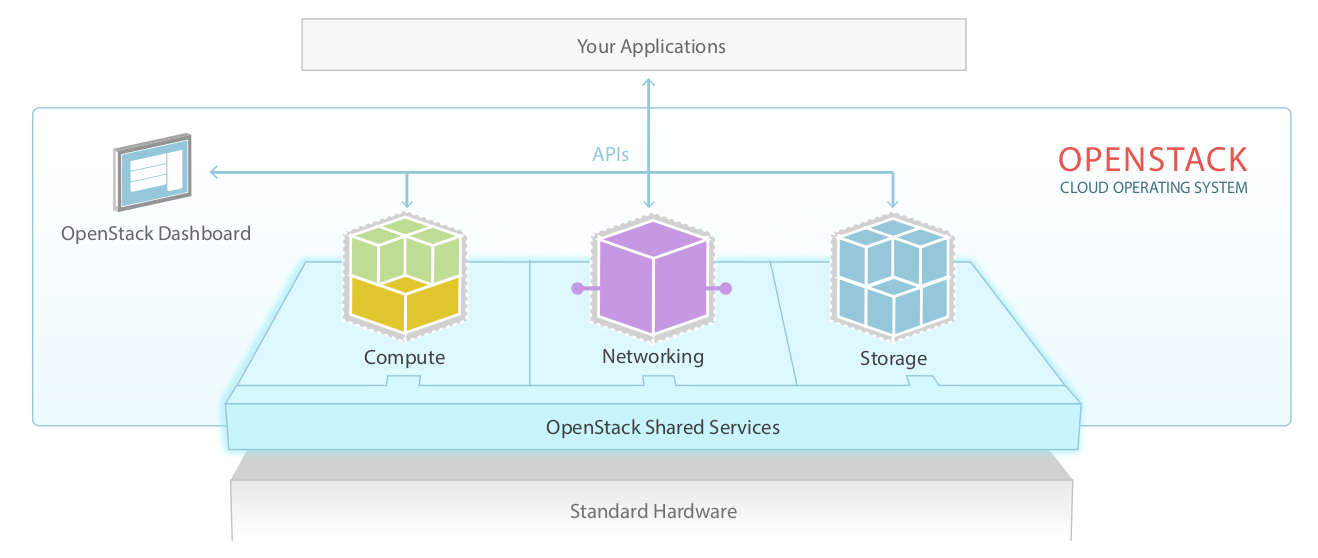
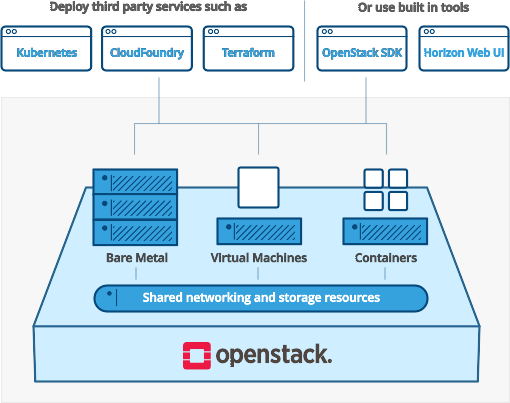
Vue haut niveau (2/2)
Historique
- Démarrage du projet en 2010
- Objectif : le Cloud Operating System libre
- Fusion de deux projets : Rackspace (Storage) et la NASA (Compute)
- Logiciel libre distribué sous licence Apache 2.0
- Naissance de l'OpenStack Foundation en 2012, rebaptisée Open Infrastructure Foundation en octobre 2020
Mission
"To produce an ubiquitous Open Source Cloud Computing platform that is easy to use, simple to implement, interoperable between deployments, works well at all scales, and meets the needs of users and operators of both public and private clouds."
OpenStack en 2021
"OpenStack is one of the top 3 most active open source projects and manages 10 million compute cores."
Les releases
- Austin (2010.1)
- Bexar (2011.1), Cactus (2011.2), Diablo (2011.3)
- Essex (2012.1), Folsom (2012.2)
- Grizzly (2013.1), Havana (2013.2)
- Icehouse (2014.1), Juno (2014.2)
- Kilo (2015.1), Liberty (2015.2)
- Mitaka (2016.1), Newton (2016.2)
- Ocata (2017.1), Pike (2017.2)
- Queens (2018.1), Rocky (2018.2)
- Stein (2019.1), Train (2019.2)
- Ussuri (2020.1), Victoria (2020.2)
- Wallaby (2021.1)
- Second semestre 2021 : Xena
Sponsors/contributeurs ...
- Editeurs : Red Hat, Canonical, Mirantis, VMware, ...
- Constructeurs/puces et serveurs : IBM, Intel
- Constructeurs/réseau : Cisco, Huawei, ...
- Constructeurs/stockage : Dell EMC
- Fournisseurs de services cloud et telco : Rackspace, Vexxhost, OVH, ...
- Telco : Deutsche Telekom, Tencent, China Mobile, NTT, ATT, ...
- Google (depuis juillet 2015)
... et utilisateurs
- BBC
- Banco Santander, Société Générale
- BMW, Volkswagen AG
- Cathay Pacific
- CERN
- China Railway
- Ministère de l'Intérieur (France)
- Walmart
- Wikimedia
- et beaucoup d'autres
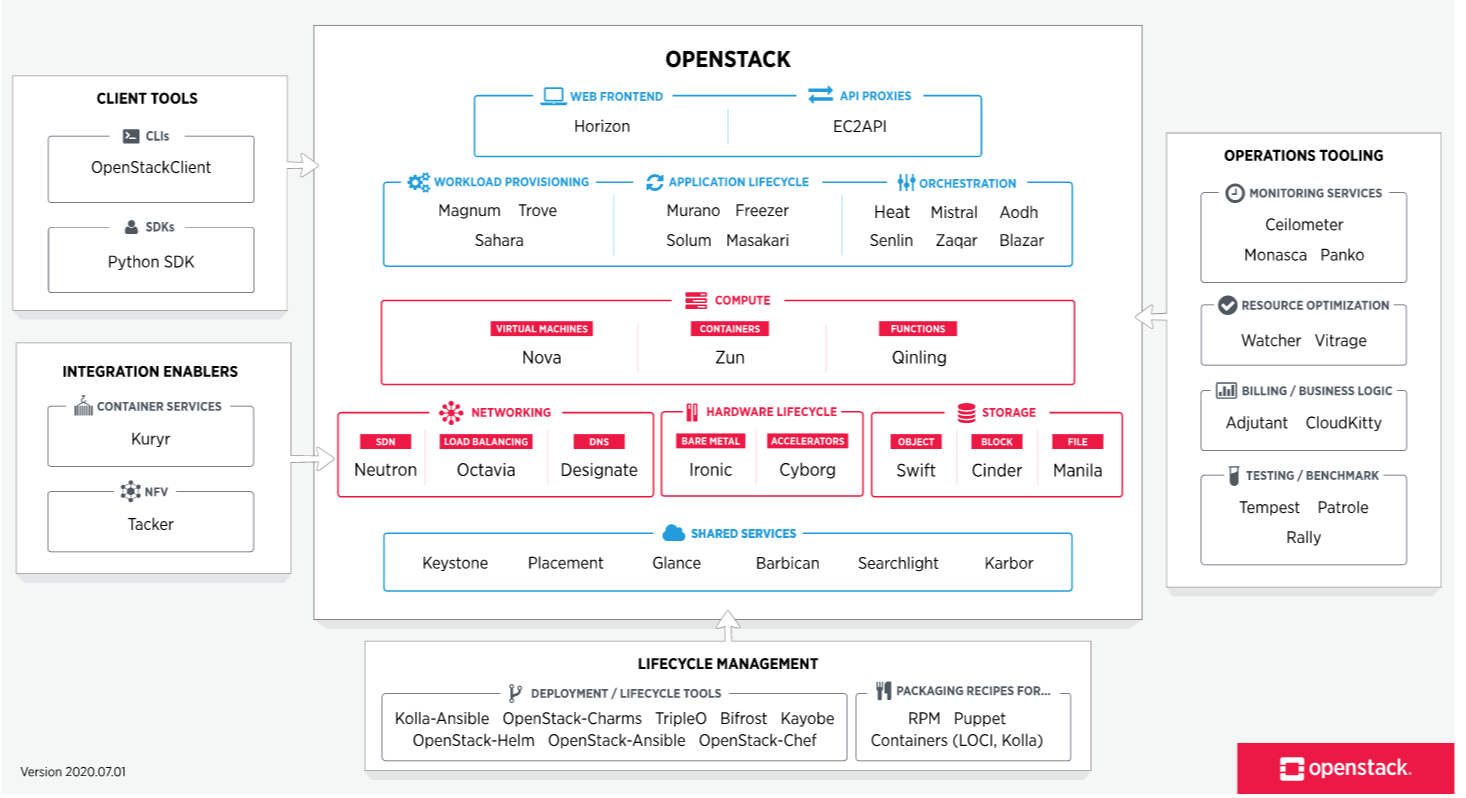
Les principaux composants d'OpenStack (1/3)
- Identity : Keystone
- Compute : Nova, Placement
- Storage : Cinder (block), Swift (object), Manila (shared file system)
- Networking : Neutron (sdn), Octavia (lbaas), Designate (dns)
- Image : Glance
- Dashboard : Horizon
- Telemetry : Ceilometer
- Alerting : AODH
- Orchestration : Heat (infra as code), Mistral (workflow), Blazar (resource reservation)
Les principaux composants d'OpenStack (2/3)
Et aussi :
- Bare metal : Ironic
- Container : Magnum
- Message Queue : Zaqar
- Database : Trove
- Data processing : Sahara
- Key management : Barbican
- Billing : Cloudkitty
- Application catalog : Murano
- ...
Les principaux composants OpenStack (3/3)
Autres :
- OpenStack sdk (bibliothèque python) et OpenStack client (CLI)
- Les outils de déploiement d'OpenStack (OSA)
- Les bibliothèques utilisées par OpenStack (Oslo)
- Les outils utilisés pour développer OpenStack (git, gerrit, zuul,...)
APIs
- Chaque composant maintient sa propre API OpenStack
- Certains composants supportent l'API AWS équivalente (Nova/EC2, Swift/S3)
Software map
La Fondation OpenStack
- Rebaptisée Open Infrastructure Foundation en 2020
- Entité de gouvernance principale et représentation juridique
- Les membres du "Board of Directors" sont issus des entreprises sponsors et des membres individuels élus
- Tout le monde peut devenir membre individuel (gratuit, pas de cotisation)
- Ressources humaines : marketing, événementiel, release management, quelques développeurs (principalement sur l’infrastructure)
- 710 organisations dans le monde, 110 000 membres, 182 pays
- Rapport annuel: https://www.openstack.org/annual-reports/2020-openinfra-foundation-annual-report/
- https://osf.dev
Open Infrastructure Foundation

Open Infrastructure
- En 2018, la Fondation OpenStack s'élargit à l'Open Infrastructure
https://openinfra.dev/about/open-infrastructure/
"The integration of open alternatives for all the different forms that compute storage and networking are taking now and in the future. The interoperable open source components are production ready, scale easily, and businesses can rely on them for real and emerging workloads."
- Au-delà d'OpenStack, des nouveaux projets sont incubés :
- Airship
- Kata Containers
- StarlingX
- Zuul
Les 4 Opens
- Open Source
- Open Design
- Open Development
- Open Community
https://governance.openstack.org/tc/reference/opens.html https://www.openstack.org/four-opens/
Ressources (1/3)
- Membres et contributeurs :
- Annonces (nouvelles versions, avis de sécurité) :
- Documentation : https://docs.openstack.org/
- API/SDK : https://developer.openstack.org/
- Bug report : https://bugs.launchpad.net/openstack
- Gouvernance : https://governance.openstack.org/
- Versions : https://releases.openstack.org/
Ressources (2/3)
- Support :
- https://stackoverflow.com/questions/tagged/openstack
- https://serverfault.com/tags/openstack/info
- openstack-discuss@lists.openstack.org
- #openstack@Freenode
- Actualités :
- Blog officiel : https://www.openstack.org/blog/
- Planet : http://planet.openstack.org/
- Expériences utilisateurs : http://superuser.openstack.org/
Ressources (3/3)
- Ressources commerciales :
- Job board :
User Survey
- Enquête réalisée chaque année par la Fondation
- Auprès des déployeurs et utilisateurs
- Résultats publiés :
Certification : Certified OpenStack Administrator (COA)
- Seule certification OpenStack existante
- Validée par la Fondation OpenStack
- Contenu :
- Essentiellement orienté utilisateur
- Pré-requis : https://www.openstack.org/coa/requirements/
- Modalités :
- Examen pratique (hands on), à distance, durée 3 heures maxi
- Coût : USD 400
- Inscription : https://www.openstack.org/coa/
- Ressources :
- Handbook : https://www.openstack.org/coa/handbook/
Communauté francophone et association

- https://openstack.fr - https://asso.openstack.fr
- Meetups : Paris, Lyon, Toulouse, Montréal, etc.
- Présence à des événements tels que Paris Open Source Summit
- Canaux de communication :
- openstack-fr@lists.openstack.org
- #openstack-fr@oftc
Fonctionnement interne
Architecture
Implémentation
- Tout est développé en Python (framework Django pour la partie web)
- Chaque projet est découpé en plusieurs services (exemple : API, scheduler, etc.)
- Réutilisation de composants existants et de bibliothèques existantes
- Utilisation des bibliothèques
oslo.*(développées par et pour OpenStack) : logs, config, etc. - Utilisation de
rootwrappour appeler des programmes sous-jacents en root
Implémentation - dépendances
- Base de données : relationnelle SQL (MariaDB-Galera)
- Communication entre les services : AMQP (RabbitMQ)
- Mise en cache : Memcached
- Load balancing: HAProxy
Modèle de développement
Statistiques (2020)
- 1375 contributeurs
- 43650 changements (commits)
https://www.openstack.org/annual-reports/2020-openinfra-foundation-annual-report
Développement du projet : en détails
- Ouvert à tous (individuels et entreprises)
- Cycle de développement de 6 mois
- Chaque cycle débute par un Project Team Gathering (PTG)
- Pendant chaque cycle a lieu un OpenStack Summit
Les outils et la communication
- Code : Git (GitHub est utilisé comme miroir)
- Revue de code (peer review) : Gerrit
- Intégration continue (CI: Continous Integration) : Zuul
- Blueprints/spécifications et bugs :
- Launchpad
- StoryBoard
- Communication : IRC et mailing-lists
- Traduction : Zanata
Développement du projet : en détails
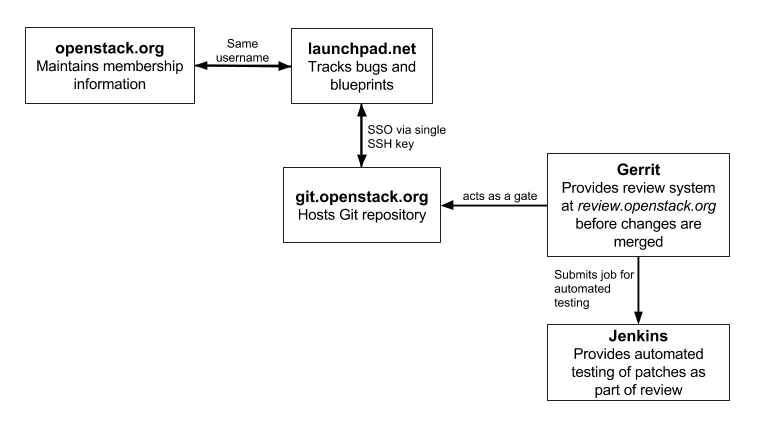
Cycle de développement : 6 mois
- Chaque release porte un nom : https://governance.openstack.org/tc/reference/release-naming.html#release-name-criteria
- Le planning est publié, exemple : https://releases.openstack.org/wallaby/schedule.html
- Milestone releases
- Freezes : Feature, Requirements, String
- RC releases
- Stable releases
- Cas particulier de certains composants : https://releases.openstack.org/reference/release_models.html
Projets
- Équipes projet (Project Teams) : https://governance.openstack.org/reference/projects/index.html
- Chaque livrable est versionné indépendamment - Semantic versioning
- https://releases.openstack.org/
Qui contribue ?
- Active Technical Contributor (ATC)
- Personne ayant au moins une contribution récente dans un projet OpenStack reconnu
- Droit de vote (TC et PTL)
- Core reviewer : ATC ayant les droits pour valider les patchs dans un projet
- Project Team Lead (PTL) : élu par les ATCs de chaque projet
- Stackalytics fournit des statistiques sur les contributions http://stackalytics.com/
Où trouver des informations sur le développement d’OpenStack
- Comment contribuer
- https://docs.openstack.org/project-team-guide/
- https://docs.opendev.org/opendev/infra-manual/
- Informations diverses, sur le wiki
- https://wiki.openstack.org/
- Les blueprints et bugs sur Launchpad/StoryBoard
- https://launchpad.net/openstack/
- https://storyboard.openstack.org/
- https://specs.openstack.org/
Où trouver des informations sur le développement d’OpenStack
- Les patchs proposés et leurs reviews sont sur Gerrit
- https://review.opendev.org/
- L’état de la CI (entre autres)
- https://zuul.opendev.org/t/openstack/status
- Le code (Git) et les tarballs sont disponibles
- https://opendev.org/openstack/
- https://tarballs.openstack.org/
- IRC
- Réseau Freenode
- Logs des discussions et infos réunions : http://eavesdrop.openstack.org/
- Mailing-lists
- http://lists.openstack.org/
Upstream Training
- Avant chaque summit
- 1,5 jours de formation, en anglais
- Apprendre à devenir contributeur à OpenStack
- Les outils
- Les processes
- Travailler et collaborer de manière ouverte
OpenStack Infra
- Équipe projet en charge de l’infrastructure de développement d’OpenStack
- Travaille comme les équipes de dev d’OpenStack et utilise les mêmes outils
- Résultat : Infrastructure as code open source https://opensourceinfra.org/
- Utilise du cloud (hybride)
OpenStack Summit
- Tous les 6 mois
- Aux USA jusqu’en 2013, aujourd'hui alternance Amérique de Nord et Asie/Europe
- Quelques dizaines au début à des milliers de participants aujourd’hui
- En parallèle : conférence (utilisateurs, décideurs) et Forum (développeurs/opérateurs, remplace une partie du précédent Design Summit)
Exemple du Summit d’avril 2013 à Portland

Exemple du Summit d’octobre 2015 à Tokyo

Exemple du Summit d’octobre 2015 à Tokyo

Exemple du Summit d’octobre 2015 à Tokyo

Exemple du Summit d’octobre 2015 à Tokyo

Project Team Gathering (PTG)
- Depuis 2017
- Au début de chaque cycle
- Roadmap fonctionnelle et discussion de sujets techniques
- Remplace une partie du précédent Design Summit
- Dédié aux développeurs, opérateurs et utilisateurs
Traduction
- SIG officielle i18n
- Seules certaines parties sont traduites, comme Horizon
- Utilisation d'une plateforme web basée sur Zanata : https://translate.openstack.org/
DevStack : faire tourner rapidement un OpenStack
Utilité de DevStack
- Déployer rapidement un OpenStack
- Utilisé par les développeurs pour tester leurs changements
- Utilisé pour faire des démonstrations
- Utilisé pour tester les APIs sans se préoccuper du déploiement
- Ne doit PAS être utilisé pour de la production
Fonctionnement de DevStack
- Support d'Ubuntu, Debian, Fedora, CentOS/RHEL, OpenSUSE
- Un script shell qui fait tout le travail : stack.sh
- Un fichier de configuration : local.conf
- Installe toutes les dépendances nécessaires (paquets)
- Clone les dépôts git (branche master par défaut)
- Lance tous les composants
Configuration : local.conf
Exemple
[[local|localrc]]
ADMIN_PASSWORD=secrete
DATABASE_PASSWORD=$ADMIN_PASSWORD
RABBIT_PASSWORD=$ADMIN_PASSWORD
SERVICE_PASSWORD=$ADMIN_PASSWORD
SERVICE_TOKEN=a682f596-76f3-11e3-b3b2-e716f9080d50
#FIXED_RANGE=172.31.1.0/24
#FLOATING_RANGE=192.168.20.0/25
#HOST_IP=10.3.4.5Conseils d’utilisation
- DevStack installe beaucoup de paquets sur la machine
- Il est recommandé de travailler dans une machine virtuelle
- Pour tester tous les composants OpenStack dans de bonnes conditions, plusieurs Go de RAM sont nécessaires
- L’utilisation de Vagrant est conseillée # OpenStack : utilisation
Généralités
Principes
- Toutes les fonctionnalités sont accessibles par l’API
- Les clients (y compris le dashboard Horizon) utilisent l’API
- Des identifiants sont nécessaires :
- utilisateur
- mot de passe
- projet (aka tenant)
- domaine
Les APIs OpenStack
- Une API par service OpenStack :
- Versionnée, la rétro-compatibilité est assurée
- Le corps des requêtes et réponses est formatté avec JSON
- Architecture REST
- Les ressources gérées sont spécifiques à un projet
Un cloud OpenStack déployé dans les règles de l'art fournit des APIs hautement disponibles.
(La haute-disponibilité des instances est un autre sujet)
Accès aux APIs
- Direct, en HTTP, via des outils comme curl
- En mode programmatique, avec une bibliothèque :
- OpenStackSDK
- D’autres implémentations, y compris pour d’autres langages (gophercloud, jclouds,...)
- Avec le CLI officiel
- Avec le dashboard Horizon (WUI)
- Avec des outils tiers de plus haut niveau tels que Terraform
Clients officiels
- OpenStack fournit des clients officiels
- Historiquement :
python-PROJETclient(bibliothèque Python et CLI) - Aujourd'hui :
openstackclient(CLI) - CLI
- L’authentification se fait en passant les identifiants par paramètres, variables d’environnement ou fichier de configuration (yaml)
- L’option
--debugaffiche les requêtes et les réponses
OpenStack Client
- CLI unifié
- Commandes du type
openstack <ressource> <action>(mode interactif disponible)openstack server list - Vise à remplacer les clients CLI spécifiques
- Permet une expérience utilisateur plus homogène
- Fichier de configuration
clouds.yaml
Keystone : identité et catalogue de services
Principes

Keystone est responsable de l'authentification, des autorisations et du catalogue de services.
- L'utilisateur standard s'authentifie auprès de Keystone
- L'administrateur intéragit régulièrement avec Keystone (pour gérer les projets, utilisateurs, autorisations,...)
APIs
- API keystone v3 --> port 5000
- Gère :
- Domaines
- Projets
- Utilisateurs, groupes
- Rôles (lien entre utilisateur et projet)
- Services et endpoints (catalogue de services)
- Fournit :
- Tokens d'authentification
Catalogue de services
- Pour chaque service, plusieurs endpoints (URLs) sont possibles en fonction de :
- la région
- le type d'interface (public, internal, admin)
Scénario d’utilisation typique
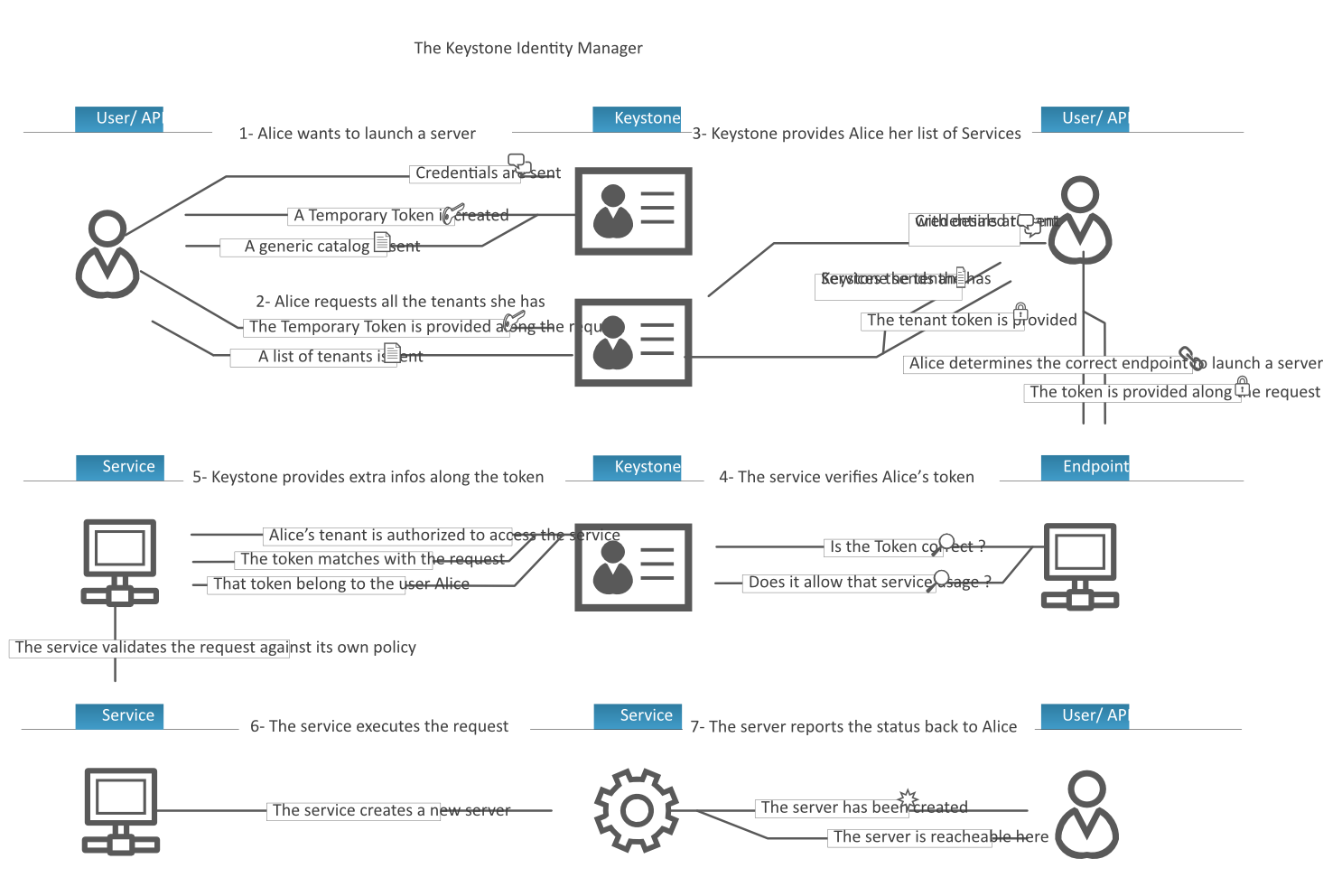
Nova : Compute
Principes

- Gère principalement les instances
- Les instances sont créées à partir des images fournies par Glance
- Les interfaces réseau des instances sont connectées à des ports Neutron
- Du stockage block peut être fourni aux instances par Cinder
Propriétés d’une instance
- Éphémère, a priori non hautement disponible
- Définie par une flavor
- Construite à partir d’une image
- Optionnel : attachement de volumes
- Optionnel : boot depuis un volume
- Optionnel : une clé SSH publique
- Optionnel : des ports réseaux
API
Ressources gérées :
- Instances
- Flavors : vcpu, ram, disque de boot
- Keypairs (clés ssh) : ressource propre à l'utilisateur (et non au projet)
Actions sur les instances
- Reboot / shutdown
- Snapshot
- Resize
- Migration (admin)
- Deletion
- Lecture des logs
- Accès console
Affinity/anti-affinity
- Demander à Nova de démarrer 2 ou plus instances :
- le plus proche possible (affinity)
- le plus éloigné possible (anti-affinity)
- Besoin de performances ou besoin de distribution/résistance aux pannes
Service metadata
- API pour les instances
- Pour obtenir la clé publique, l'adresse IP, les user data,...
- URL spécifique : `curl http://169.254.169.254/openstack
Cinder : Stockage block
Principes

- Fournit des volumes (stockage block) attachables aux instances (/dev)
- Gère différents types de volume
- Gère snapshots et backups de volumes
Utilisation
- Volume supplémentaire (et stockage persistant) sur une instance
- Boot from volume : l’OS est sur le volume
- Fonctionnalité de backup vers un object store (Swift ou Ceph)
Glance : registre d'images
Principes

- Registre d'images et de snapshots
- Propriétés sur les images
API
- API v2 : version courante, gère images et snapshots d'instances
Types d’images
Glance supporte un large éventail de types d’images, limité par le support de la technologie sous-jacente à Nova :
- raw
- qcow2
- ami
- vmdk
- iso
Propriétés des images dans Glance
L’utilisateur peut définir un certain nombre de propriétés dont certaines seront utilisées lors de l’instanciation :
- Type d’image
- Architecture
- Distribution
- Version de la distribution
- Espace disque minimum
- RAM minimum
Visibilité et partage des images
- Image publique : accessible à tous les projets
- Par défaut, seul l'administrateur peut rendre une image publique
- Image privée : accessible uniquement au projet auquel elle appartient
- Image partagée : accessible à un ou plusieurs autre(s) projet(s)
Images cloud
Une image cloud c’est :
- Une image disque contenant un OS déjà installé
- Un OS sachant parler à l’API de metadata du cloud (avec
cloud-init) - Détails : https://docs.openstack.org/image-guide/openstack-images.html
La plupart des distributions Linux fournissent des images régulièrement mises à jour :
- Ubuntu : https://cloud-images.ubuntu.com/
- Debian : https://cdimage.debian.org/cdimage/openstack/
- CentOS : https://cloud.centos.org/centos/
Cloud-init
- Cloud-init est un moyen de tirer parti de l’API de metadata, et notamment des user data
- Intégré par défaut dans la plupart des images cloud
- À partir des user data, cloud-init effectue les opérations de personnalisation de l’instance
- cloud-config est un format possible de user data
Exemple cloud-config :
#cloud-config
mounts:
- [ vda2, /var/www ]
packages:
- apache2
package_update: trueNeutron : réseau
API

L’API permet notamment de manipuler les ressources :
- Réseau : niveau 2
- Sous-réseau : niveau 3
- Port : attachable à une interface sur une instance, un load-balancer, etc.
- Routeur
- IP flottante
- Groupe de sécurité
Les IP flottantes
- Permettent d'exposer une instance au réseau externe
- En plus des fixed IPs portées par les instances
- Non portées directement par les instances
- Allocation (réservation par le projet) d'une IP depuis un pool
- Association à un port d'une IP allouée
Les groupes de sécurité
- Équivalents à un pare-feu devant chaque instance
- Une instance peut être associée à un ou plusieurs groupes de sécurité
- Gestion des accès en entrée (ingress) et sortie (egress)
- Règles de filtrage par protocole (TCP/UDP/ICMP) et par port
- La source d'une règle est soit une adresse IP, un réseau ou un autre groupe de sécurité
Fonctionnalités supplémentaires
Outre les fonctions réseau de base niveaux 2 et 3, Neutron peut fournir d’autres services :
- VPN : permet d’accéder à un réseau privé sans IP flottantes
- QoS : règles de gestion de la bande passante
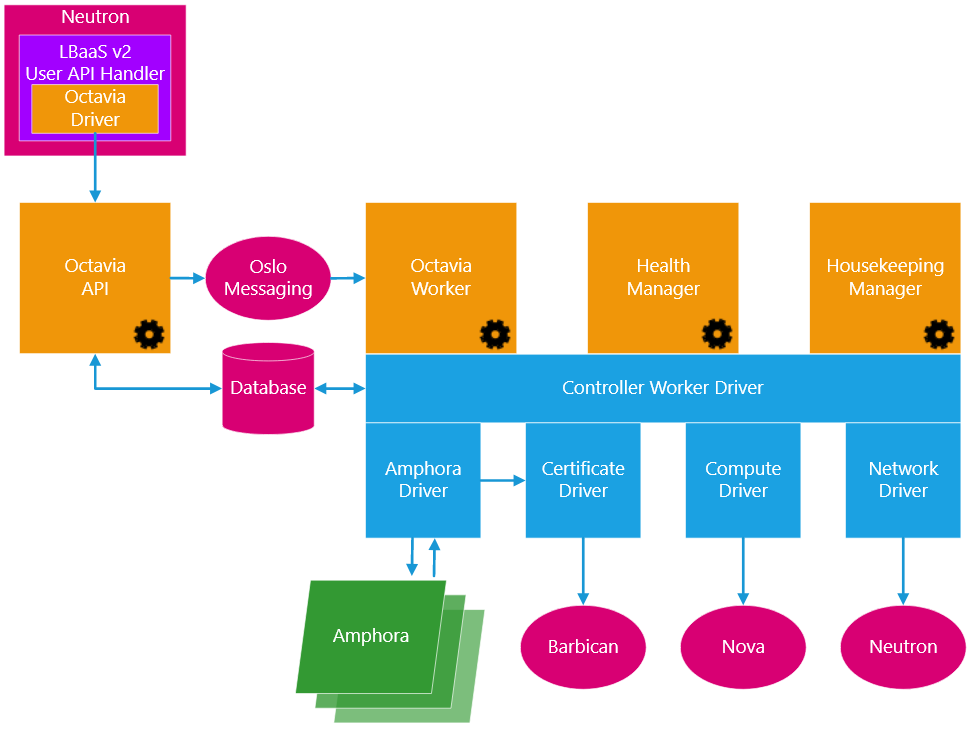
Octavia : load balancer
Principes

- Fournit des fonctionnalités de load balancing aux projets
- Load balancing implémenté par des instances spécifiques, les amphores
- Gestion de la haute-disponibilité des load balancers eux-mêmes
- Agnostique des technologies sous-jacentes
- Basé par défaut sur HAProxy
Composants : vue aérienne
API
Version courante : V2
L'API Octavia permet de gérer les ressources suivantes :
- Load balancer
- Listener
- Pool
- Member
- Health monitor
- Rules
- Policies
Heat : Orchestration
Généralités

- Heat est la solution native OpenStack du service d'orchestration
- Il permet de décrire, dans des templates YAML, des ensembles cohérents de ressources virtuelles
- Heat fournit une API de manipulation de stacks à partir de templates
- Un template Heat suit le format HOT (Heat Orchestration Template)
- Il est possible de générer des templates interactivement avec le dashboard Horizon
Exemple de template
heat_template_version: 2018-08-31
description: Simple template to deploy a single compute instance
parameters:
instance_name:
type: string
label: Instance Name
default: my_instance
subnet_id:
type: string
resources:
instance:
type: OS::Nova::Server
properties:
name: { get_param: instance_name }
image: cirros
flavor: m1.small
networks:
- port: { get_resource: instance_port }
instance_port:
type: OS::Neutron::Port
properties:
network_id: { get_param: subnet_id }
fixed_ips:
- subnet_id: { get_param: subnet_id }
outputs:
fixed_ip: { get_attr: [ instance, first_address ] Horizon : Dashboard web
Principes

- Fournit une interface web (WUI) à l'utilisateur et à l'administrateur OpenStack
- S'appuie sur les services déployés pour déterminer les fonctionnalités offertes dans le WUI
- Log in sans préciser un projet : Horizon détermine la liste des projets accessibles
Utilisation
- Fonctionne bien avec Firefox et Chrome
- Echanges HTTPS
- Authentification de type username/password
- Notion de projet courant, possibilité de basculer d'un projet à l'autre
- Une zone “admin” restreinte
- Support multilingue
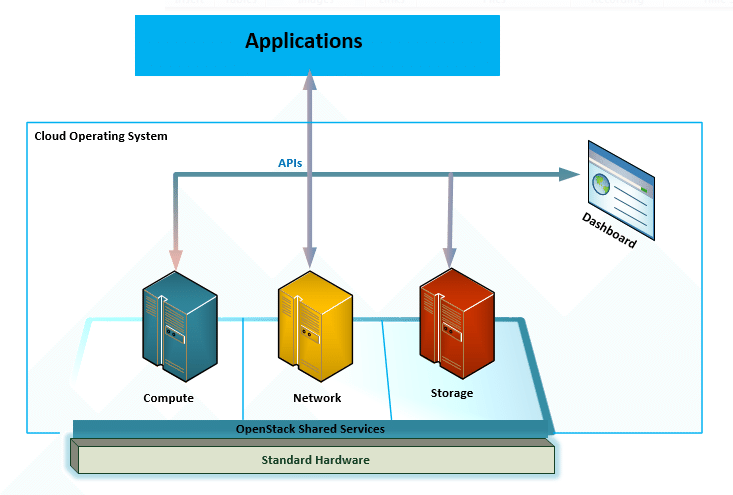
Déployer OpenStack
Ce qu’on va voir
- Installer OpenStack à la main https://docs.openstack.org/install-guide/
- Donc comprendre son fonctionnement
- Passer en revue chaque composant plus en détails
- Tour d’horizon des solutions de déploiement
Architecture simplifiée et principaux composants
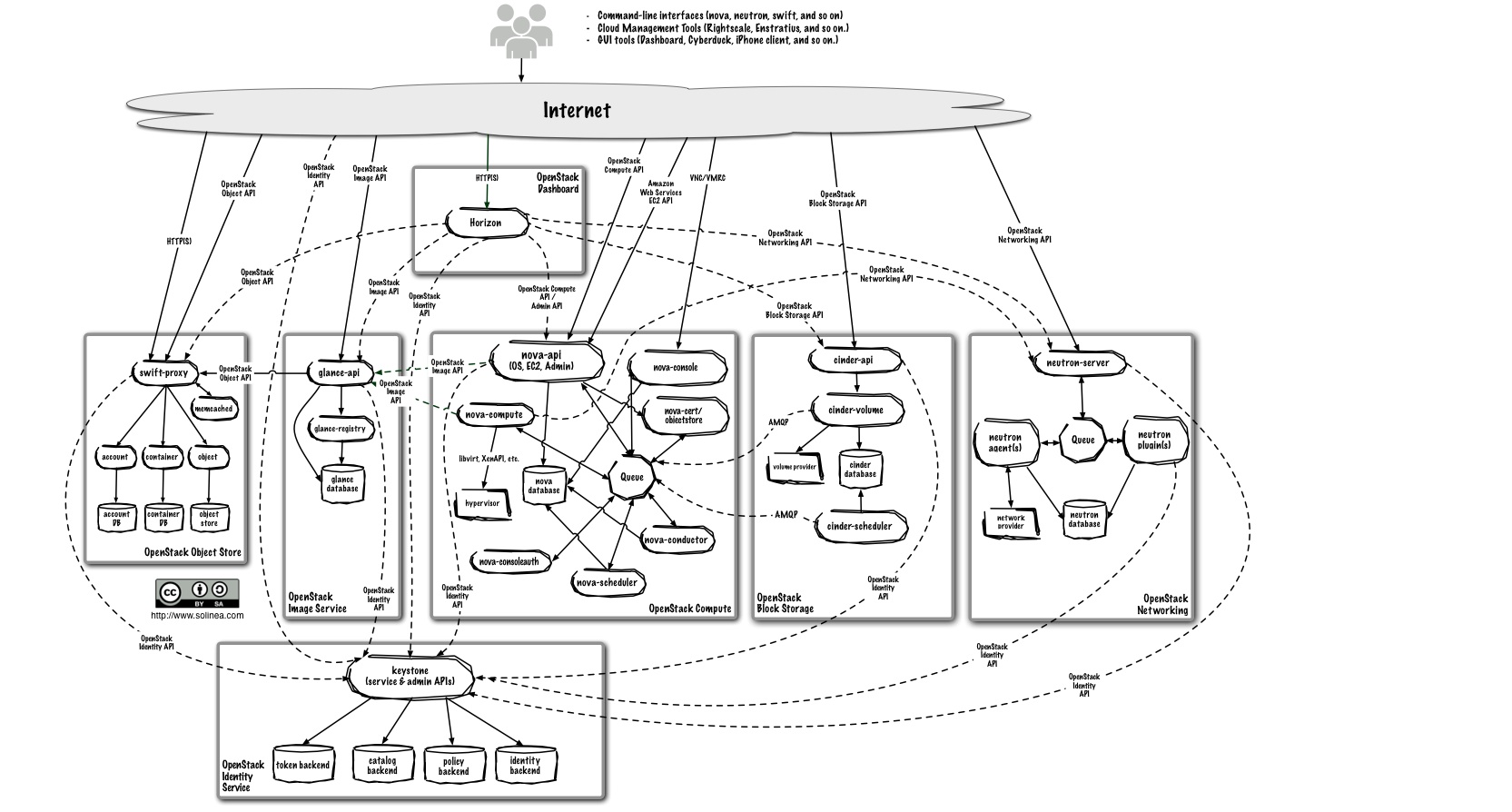
Architecture détaillée
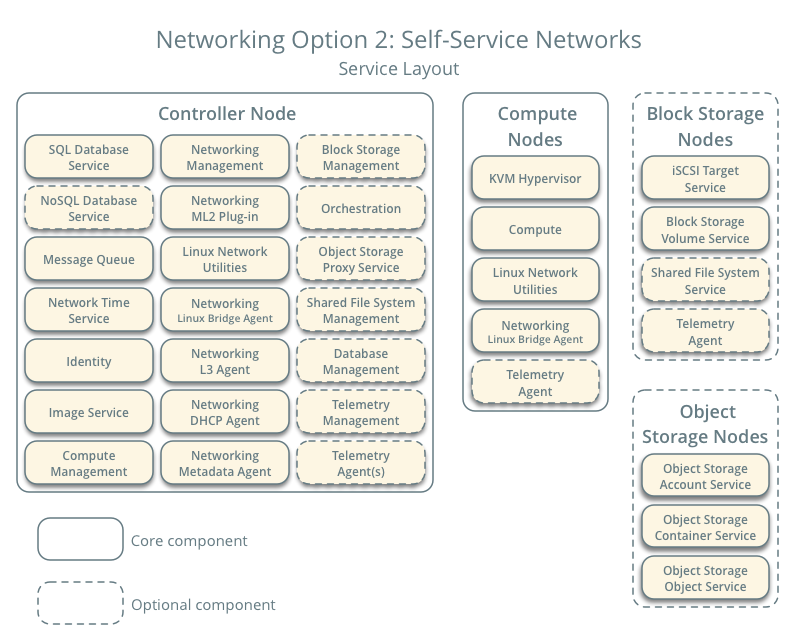
Architecture services
Quelques éléments de configuration généraux
- Il s'agit de fournir un catalogue de services (APIs) hautement disponibles
- Tous les composants doivent être configurés pour communiquer avec Keystone
- La plupart doivent être configurés pour communiquer avec MariaDB et RabbitMQ
- Les composants découpés en plusieurs services ont parfois un fichier de configuration par service
- Le fichier de configuration
policy.jsonprécise les droits nécessaires pour chaque appel API
Système d’exploitation
- OS Linux avec Python
- Ubuntu
- Debian, Fedora, CentOS
- Red Hat
- SUSE
Python

- OpenStack est compatible Python 2.7
- Comptabilité Python 3 presque complète
- Afin de ne pas réinventer la roue, beaucoup de dépendances sont nécessaires
Base de données MariaDB
- Permet de stocker la majorité des données gérées par OpenStack
- Chaque composant a sa propre base
- OpenStack utilise l’ORM Python SQLAlchemy
- Support théorique équivalent à celui de SQLAlchemy (et support des migrations)
- MariaDB est l’implémentation la plus largement testée et utilisée
- SQLite est principalement utilisé dans le cadre de tests et démo
- Certains déploiements fonctionnent avec PostgreSQL
![]()
![]()
Passage de messages
- AMQP : Advanced Message Queuing Protocol
- Messages, file d’attente, routage
- Les processus OpenStack communiquent via AMQP
- Plusieurs implémentations possibles : Qpid, 0MQ, etc.
- RabbitMQ par défaut
RabbitMQ
- RabbitMQ est implémenté en Erlang
- Une machine virtuelle Erlang est donc nécessaire
“Hello world” RabbitMQ
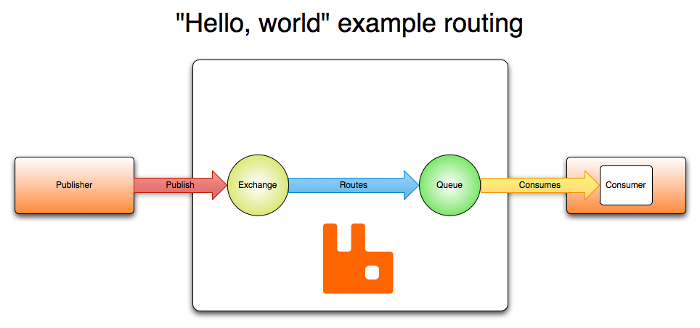
Cache Memcached
- Plusieurs services tirent parti d'un mécanisme de cache
- Memcached est l'implémentation par défaut
Keystone : Authentification, autorisation et catalogue de services
Installation et configuration
- Paquet APT : keystone
- Intégration serveur web WSGI (Apache par défaut)
- Fichier de configuration:
/etc/keystone/keystone.conf - Backends utilisateurs/groupes : SQL, LDAP (ou Active Directory)
- Backends projets/rôles/services/endpoints : SQL
- Backends tokens : SQL, Memcache, aucun (suivant le type de tokens)
Drivers pour tokens
- Uuid
- PKI
- Fernet
Bootstrap
- Création des services et endpoints (à commencer par Keystone)
- Création d'utilisateurs, groupes, domaines
- Fonctionnalité de bootstrap
Nova : Compute
Nova api
- Double rôle
- API de manipulation des instances par l’utilisateur
- API à destination des instances : API de metadata
- L’API de metadata doit être accessible à l’adresse
http://169.254.169.254/ - L’API de metadata fournit des informations de configuration personnalisées à chacune des instances
Nova compute
- Pilote les instances (machines virtuelles ou physiques)
- Tire partie de libvirt ou d’autres APIs comme XenAPI
- Drivers : libvirt (KVM, LXC, etc.), XenAPI, VMWare vSphere, Ironic
- Permet de récupérer les logs de la console et une console VNC
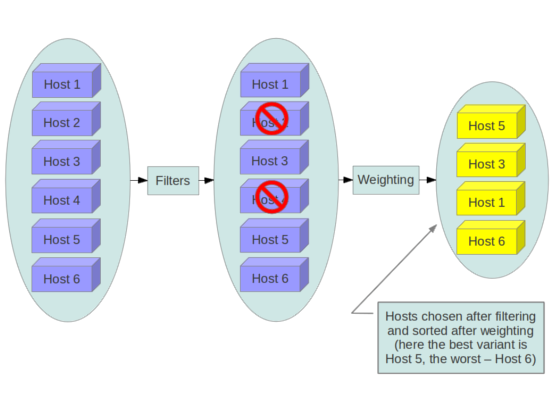
Nova scheduler
- Service qui distribue les demandes d’instances sur les nœuds compute
- Filter, Chance, Multi Scheduler
- Filtres, par défaut : AvailabilityZoneFilter,RamFilter,ComputeFilter
- Tri par poids, par défaut : RamWeigher
Le scheduler Nova en action
Nova conductor
- Service facultatif qui améliore la sécurité
- Fait office de proxy entre les nœuds compute et la BDD
- Les nœuds compute, vulnérables, n’ont donc plus d’accès à la BDD
Glance : Registre d’images
Backends
- Swift ou S3
- Ceph
- HTTP
- Répertoire local
Installation
- Paquet APT : glance-api
Neutron : Réseau en tant que service
Principes
- Software Defined Networking (SDN)
- Auparavant Quantum et nova-network
- neutron-server : fournit l’API
- Agent DHCP : fournit le service de DHCP pour les instances
- Agent L3 : gère la couche 3 du réseau, le routage
- Plugin : LinuxBridge par défaut, d’autres implémentations libres/propriétaires, logicielles/matérielles existent
Fonctionnalités supplémentaires
Outre les fonctions réseau de base niveaux 2 et 3, Neutron peut fournir d’autres services :
- Load Balancing (HAProxy, ...)
- Firewall (vArmour, ...) : diffère des groupes de sécurité
- VPN (Openswan, ...) : permet d’accéder à un réseau privé sans IP flottantes
Ces fonctionnalités se basent également sur des plugins
Plugins ML2
- Modular Layer 2
- LinuxBridge
- OpenVSwitch
- OpenDaylight
- Contrail, OpenContrail
- Nuage Networks
- VMWare NSX
- cf. OpenFlow
Implémentation
- Chaque réseau est un bridge
- Les bridges sont étendus entre les machines via des tunnels (type VXLAN) si nécessaires
- Neutron tire partie des namespaces réseaux du noyau Linux pour permettre l’IP overlapping
- Le proxy de metadata est un composant qui permet aux instances isolées dans leur réseau de joindre l’API de metadata fournie par Nova
Schéma
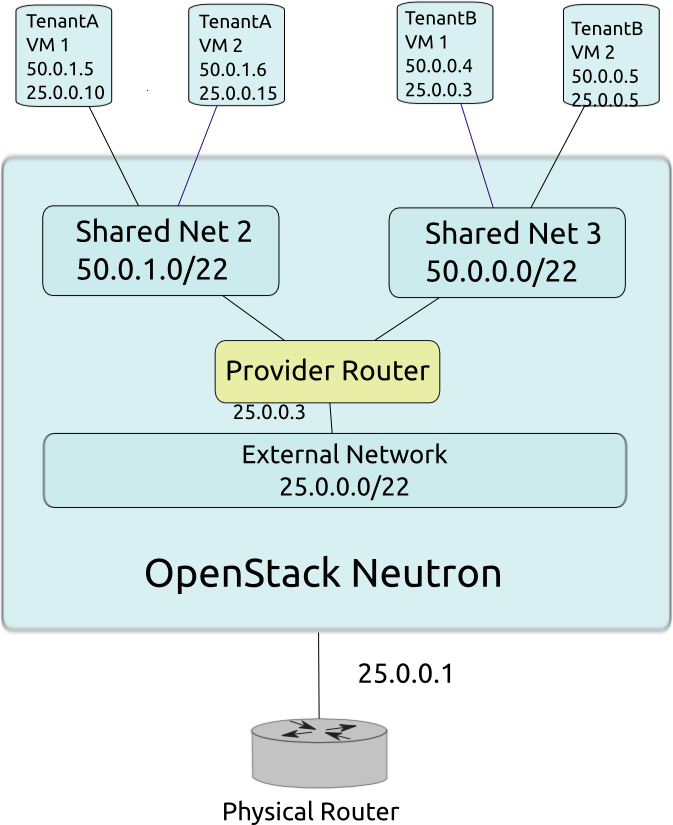
Schéma
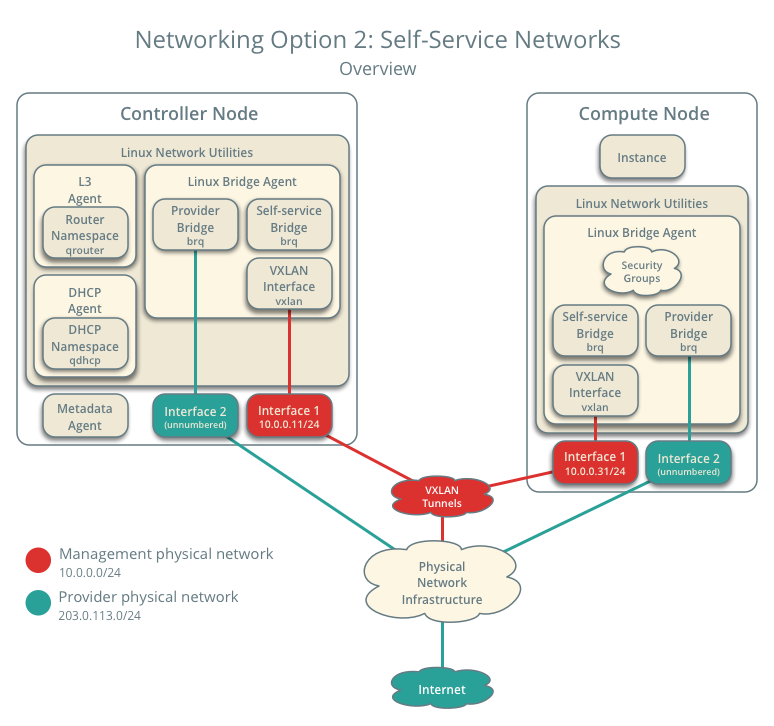
Cinder : Stockage block
Principes
- Auparavant nova-volume
- Fournit des volumes
- Attachement des volumes via iSCSI par défaut
Installation
- Paquet cinder-api : fournit l’API
- Paquet cinder-volume : création et gestion des volumes
- Paquet cinder-scheduler : distribue les demandes de création de volume
- Paquet cinder-backup (optionnel) : backup vers un object store
Backends
- Utilisation de plusieurs backends en parallèle possible
- LVM (par défaut)
- GlusterFS
- Ceph
- Systèmes de stockage propriétaires type NetApp
- DRBD
Horizon : Dashboard web
Principes
- Horizon est un module Django
- OpenStack Dashboard est l’implémentation officielle de ce module
- Généralement déployé sur les contrôleurs
Configuration
local_settings.py- Les services apparaissent dans Horizon s’ils sont répertoriés dans le catalogue de services de Keystone
Swift : Stockage objet
Principes
- SDS : Software Defined Storage
- Utilisation de commodity hardware
- Théorème CAP : on en choisit deux
- Architecture totalement acentrée
- Pas de base de données centrale
Implémentation
- Proxy : serveur API par lequel passent toutes les requêtes
- Object server : serveur de stockage
- Container server : maintient des listes d’objects dans des containers
- Account server : maintient des listes de containers dans des accounts
- Chaque objet est répliqué n fois (3 par défaut)
Le ring
- Problème : comment décider quelle donnée va sur quel object server
- Le ring est découpé en partitions
- On situe chaque donnée dans le ring afin de déterminer sa partition
- Une partition est associée à plusieurs serveurs
Schéma
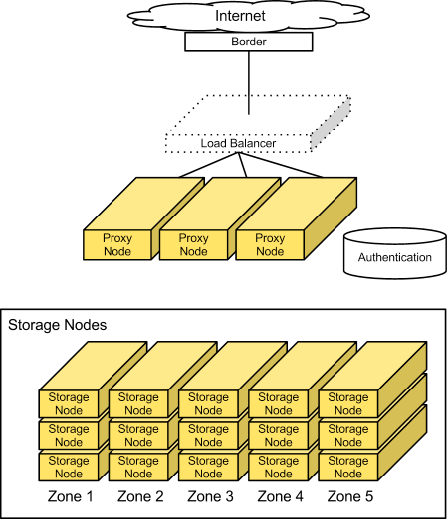
Ceilometer : Collecte de métriques
Surveiller l’utilisation de son infrastructure avec Ceilometer
- Indexer et stocker différentes métriques concernant l’utilisation des différents services du cloud
- Fournir des APIs permettant de récupérer ces données
- Base pour construire des outils de facturation (exemple : CloudKitty)
Ceilometer
- Récupère les données et les stocke
- Historiquement : stockage MongoDB
- Aujourd'hui : stockage Gnocchi
Gnocchi : time-series database
- Pourquoi Gnocchi ? Palier aux problème de scalabilité de Ceilometer + MongoDB
- Initié par des développeurs de Ceilometer et intégré à l’équipe projet Ceilometer
- Fournit une API pour lire et écrire les données
- Se base sur une BDD relationnelle et un système de stockage objet
Heat : Orchestration des ressources
Architecture
- heat-api
- heat-engine
Quelques autres composants intéressants
Trove : Database as a Service
- trove-api : API
- trove-taskmanager : gère les instances BDD
- trove-guestagent : agent interne à l’instance
Designate : DNS as a Service
- Gère différents backends : BIND, PowerDNS, etc.
Barbican : Key management as a Service
- Backends possibles :
- Fichiers chiffrés
- PKCS#11
- KMIP
- Dogtag
Magnum : Container Infrastructure as a Service
- Backends: Swarm, Kubernetes
OpenStack en production et opérations
Bonnes pratiques pour un déploiement en production
Quels composants dois-je installer ?
- Keystone est indispensable
- L’utilisation de Nova va de paire avec Glance et Neutron
- Cinder et Swift s'apprécient en fonction des besoins de stockage
- Swift peut être utilisé indépendemment des autres composants
- Heat coûte peu
- Les services plus haut niveau s'évaluent au cas par cas
Penser dès le début aux choix structurants
- Distribution et méthode de déploiement
- Politique de mise à jour
- Drivers/backends : hyperviseur, stockage block, etc.
- Réseau : quelle architecture et quels drivers
Les différentes méthodes d’installation
- DevStack est à oublier pour la production
- Le déploiement à la main comme vu précédemment n’est pas recommandé car peu maintenable
- Distributions OpenStack packagées et prêtes à l’emploi
- Distributions classiques et gestion de configuration
- Déploiement continu
Mises à jour entre versions majeures
- OpenStack supporte les mises à jour N → N+1
- Swift : très bonne gestion en mode rolling upgrade
- Autres composants : tester préalablement avec vos données
- Lire les release notes
- Cf. articles de blog du CERN https://techblog.web.cern.ch/techblog/
Mises à jour dans une version stable
- Fourniture de correctifs de bugs majeurs et de sécurité
- OpenStack intègre ces correctifs sous forme de patchs dans la branche stable
- Publication de point releases intégrant ces correctifs issus de la branche stable
- Durée variable du support des versions stables, dépendant de l’intérêt des intégrateurs
Assigner des rôles aux machines
Beaucoup de documentations font référence à ces rôles :
- Controller node : APIs, BDD, AMQP
- Network node : DHCP, routeur, IPs flottantes
- Compute node : Hyperviseur/pilotage des instances
Ce modèle simplifié n’est pas HA.
Haute disponibilité
Haute disponibilité du IaaS
- MySQL/MariaDB, RabbitMQ : HA classique (Galera, Clustering)
- Les services APIs sont stateless et HTTP : scale out et load balancers
- La plupart des autres services OpenStack sont capables de scale out également
Guide HA : https://docs.openstack.org/ha-guide/
Conférences par Florian Haas, City Network : https://www.openstack.org/community/speakers/profile/398/florian-haas
Haute disponibilité de l’agent L3 de Neutron
- Distributed Virtual Router (DVR)
- L3 agent HA (VRRP)
Considérations APIs
- Des URLs uniformes pour toutes les APIs :
- Utiliser un reverse proxy
- Mettre à jour le catalogue de services
- Apache/mod_wsgi pour servir les APIs lorsque cela est possible (Keystone, etc.)
Guide Operations : https://docs.openstack.org/openstack-ops/content/
Découpage réseau
- Management network : réseau d’administration
- Data/instances network : réseau pour la communication inter instances
- External network : réseau externe, dans l’infrastructure réseau existante
- Storage network : réseau pour le stockage Cinder/Swift
- API network : réseau contenant les endpoints API
Considérations liées à la sécurité
- Indispensable : HTTPS sur l’accès des APIs à l’extérieur
- Sécurisation des communications MySQL/MariaDB et RabbitMQ
- Un accès MySQL/MariaDB par base et par service
- Un utilisateur Keystone par service
- Limiter l’accès en lecture des fichiers de configuration (mots de passe, token)
- Veille sur les failles de sécurité : OSSA (OpenStack Security Advisory), OSSN (... Notes)
Guide sécurité : https://docs.openstack.org/security-guide/
Segmenter son cloud
- Host aggregates : machines physiques avec des caractéristiques similaires
- Availability zones : machines dépendantes d’une même source électrique, d’un même switch, d’un même DC, etc.
- Regions : chaque région a son API
- Cells : permet de regrouper plusieurs cloud différents sous une même API
Host aggregates / agrégats d’hôtes
- Spécifique Nova
- L’administrateur définit des agrégats d’hôtes via l’API
- L’administrateur associe flavors et agrégats via des couples clé/valeur communs
- 1 agrégat ≡ 1 point commun, ex : GPU
- L’utilisateur choisit un agrégat à travers son choix de flavor à la création d’instance
Availability zones / zones de disponibilité
- Spécifique Nova et Cinder
- Groupes d’hôtes
- Découpage en termes de disponibilité : Rack, Datacenter, etc.
- L’utilisateur choisit une zone de disponibilité à la création d’instance
- L’utilisateur peut demander à ce que des instances soient démarrées dans une même zone, ou au contraire dans des zones différentes
Régions
- Générique OpenStack
- Équivalent des régions d’AWS
- Un service peut avoir différents endpoints dans différentes régions
- Chaque région est autonome
- Cas d’usage : cloud de grande ampleur (comme certains clouds publics)
Cells / Cellules
- Spécifique Nova
- Un seul nova-api devant plusieurs cellules
- Chaque cellule a sa propre BDD et file de messages
- Ajoute un niveau de scheduling (choix de la cellule)
Packaging d’OpenStack - Ubuntu
- Le packaging est fait dans de multiples distributions, RPM, DEB et autres
- Ubuntu est historiquement la plateforme de référence pour le développement d’OpenStack
- Le packaging dans Ubuntu suit de près le développement d’OpenStack, et des tests automatisés sont réalisés
- Canonical fournit la Ubuntu Cloud Archive, qui met à disposition la dernière version d’OpenStack pour la dernière Ubuntu LTS
Ubuntu Cloud Archive (UCA)

Packaging d’OpenStack dans les autres distributions
- OpenStack est intégré dans les dépôts officiels de Debian
- Red Hat propose RHOS/RDO (déploiement basé sur TripleO)
- Comme Ubuntu, le cycle de release de Fedora est synchronisé avec celui d’OpenStack
TripleO
- OpenStack On OpenStack
- Objectif : pouvoir déployer un cloud OpenStack (overcloud) à partir d’un cloud OpenStack (undercloud)
- Autoscaling du cloud lui-même : déploiement de nouveaux nœuds compute lorsque cela est nécessaire
- Fonctionne conjointement avec Ironic pour le déploiement bare-metal
Déploiement bare-metal
- Le déploiement des hôtes physiques OpenStack peut se faire à l’aide d’outils dédiés
- MaaS (Metal as a Service), par Ubuntu/Canonical : se couple avec Juju
- Crowbar / OpenCrowbar (initialement Dell) : utilise Chef
- Ironic via TripleO
Gestion de configuration
- Ansible, Puppet, Chef, CFEngine, Saltstack, etc.
- Ces outils peuvent aider à déployer le cloud OpenStack
- ... mais aussi à gérer les instances (section suivante)
Modules Puppet, Playbooks Ansible
- Puppet OpenStack et OpenStack Ansible : modules Puppet et playbooks Ansible
- Développés au sein du projet OpenStack
- https://wiki.openstack.org/wiki/Puppet
- https://docs.openstack.org/openstack-ansible/
Déploiement continu
- OpenStack maintient un master (trunk) toujours stable
- Possibilité de déployer au jour le jour le
master(CD : Continous Delivery) - Nécessite la mise en place d’une infrastructure importante
- Facilite les mises à jour entre versions majeures
Test et validation : Tempest
- Suite de tests d’un cloud OpenStack
- Effectue des appels à l’API et vérifie le résultat
- Est très utilisé par les développeurs via l’intégration continue
- Le déployeur peut utiliser Tempest pour vérifier la bonne conformité de son cloud
- Cf. aussi Rally
Gérer les problèmes
Les réflexes en cas d’erreur ou de comportement erroné
- Travaille-t-on sur le bon projet ?
- Est-ce que l’API renvoie une erreur ? (le dashboard peut cacher certaines informations)
- Si nécessaire d’aller plus loin :
- Regarder les logs sur le(s) contrôleur(s) (/var/log/<composant>/*.log)
- Regarder les logs sur le compute node et le network/controller node si le problème est spécifique réseau/instance
- Éventuellement modifier la verbosité des logs dans la configuration
Est-ce un bug ?
- Si le client CLI crash, c’est un bug
- Si le dashboard web ou une API renvoie une erreur 500, c’est peut-être un bug
- Si les logs montrent une stacktrace Python, c’est un bug
- Sinon, à vous d’en juger
Opérations
Gestion des logs
- Centraliser les logs
- Logs d'API
- Logs autres composants OpenStack
- Logs BDD, AMQP, etc.
Backup
- Bases de données
- Mécanisme de déploiement, plutôt que backup des fichiers de configuration
Monitoring
- Réponse des APIs
- Vérification des services OpenStack et dépendances
Utilisation des quotas
- Limiter le nombre de ressources allouables
- Par utilisateur ou par projet
- Support dans Nova
- Support dans Cinder
- Support dans Neutron
OpenStack : déployer avec Ansible
Rappels : Ansible
- Déploiement de configuration
- Masterless, agentless
- Tâches, playbooks, rôles, variables (yaml)
- Inventaire
- Collections de modules
- Écrit en Python
OpenStack-Ansible (OSA)
- Projet officiel OpenStack : https://opendev.org/openstack/openstack-ansible
- Déployer et maintenir un cloud OpenStack en production, choix de la release
- Ansible : ensemble de playbooks, de rôles et de scripts (python, bash)
- Support de Debian/Ubuntu, CentOS, openSUSE
- Déploiement à partir des sources (git clone)
- Services déployés dans des conteneurs LXC
- Nécessité de créer des bridges sur les hosts : support LinuxBridge et Open vSwitch
- Déploiement de Ceph via
ceph-ansible: https://github.com/ceph/ceph-ansible
Principaux composants supportés
- Keystone
- Nova
- Cinder
- Glance
- Neutron
- Octavia
- Swift
- Heat
- Horizon
- Ceilometer, Aodh
- Tempest
Mise en oeuvre de la haute disponibilité
- HAProxy -> Keepalived
- MySQL -> Galera cluster
- RabbitMQ -> Clustering
- Memcached -> Farming
Réseau
- L2 : LinuxBridge ou Open vSwitch
- Routeur virtuel : centralisé ou distribué (DVR)
Rsyslog centralisé (optionnel)
- Un conteneur
rsyslog - Tous les services lui transmettent les logs
- Ce
rsyslogpeut lui même transférer les logs ailleurs
OSA en multi-régions
- Un déploiement OSA par région
- Un déploiement pour le Keystone central
OSA workflow

Machine de déploiement
- Composant principal :
openstack-ansible - Scripts
- Playbooks
- Inventaire dynamique
$ git clone https://opendev.org/openstack/openstack-ansible /opt/openstack-ansible
$ cd /opt/openstack-ansible
$ git checkout stable/<release>Récupérer les rôles
- Un rôle par service
- URLs et versions définies dans
openstack-ansible/ansible-role-requirements.yml openstack-ansible/scripts/bootstrap-ansible.shinstalle ansible et télécharge les rôles dans/etc/ansible/roles
Configurer
/etc/openstack_deploy/./openstack_user_config.yml-> description de l'infra et des réseaux./user_variables.yml-> configuration des services./user_secrets.yml
Déployer
Dans /opt/openstack-ansible/playbooks, avec le wrapper openstack-ansible :
- Création des conteneurs LXC :
openstack-ansible setup-hosts.yml
- Déploiement des services infra :
openstack-ansible setup-infrastructure.yml
- Déploiement des services OpenStack :
openstack-ansible setup-openstack.yml
Enchaînement automatique :
openstack-ansible setup-everything.yml
Mettre à jour
Dans /opt/openstack-ansible :
git pullgit checkoutde la release ciblescripts/bootstrap-ansible.shcd playbooks; openstack-ansible setup-everything.yml
Sécurité
- Rôle
ansible-hardening - Lancée par
setup-hosts.yml - Durcissement des hosts
- Implémente les exigences exprimées dans le Security Technical Implementation Guide
openstack-ansible-ops
Outils pour OSA
- Exemples :
- Supprimer les anciens venvs
- Restaurer RabbitMQ
Simuler des pannes
Concevoir une application pour le Cloud
La référence : les 12 facteurs
“The Twelve-Factor App” https://12factor.net/fr/
- Publié par Heroku https://www.heroku.com/what/
- Ecrit par des développeurs, des architectes et des ops
- Recueil de préconisations techniques issues d'expériences terrain
- Destiné aux développeurs et aux personnes en charge du déploiement et du Run
- Applicable quel que soit le langage de programmation
Les 12 facteurs en détails (1/2)
- Base de code : unique, suivie dans un VCS, plusieurs déploiements
- Dépendances : les isoler et les déclarer explicitement
- Configuration : différencier les environnements via les variables de conf.
- Services externes : les traiter comme des ressources attachées
- Build, release, run : séparer strictement les étapes d’assemblage et d’exécution
- Processus : exécuter l’application comme un ou plusieurs processus sans état
Les 12 facteurs en détails (2/2)
- Ports : exporter les services de l'application via des ports TCP
- Mise à l'échelle : utiliser le modèle de processus
- Jetable : maximisez la robustesse avec des démarrages rapides et des arrêts en douceur
- Parité dev/prod : gardez les différents environnements aussi proches que possible
- Logs : les traiter comme des flux d’évènements
- Processus d’administration et de maintenance : les lancer comme des processus one-off
Penser son application “cloud ready” 1/3
- Une base de code unique suivie dans un VCS (Git,...)
- Une configuration par environnement
- Architecture distribuée plutôt que monolithique
- Facilite le passage à l’échelle
- Limite les domaines de failure
- Couplage faible entre les composants
Penser son application “cloud ready” 2/3
- Bus de messages pour les communications inter-composants
- Stateless : permet de multiplier les routes d’accès à l’application
- Dynamicité : l’application doit s’adapter à son environnement et se reconfigurer lorsque nécessaire
- Permettre le déploiement et l’exploitation par des outils d’automatisation
Penser son application “cloud ready” 3/3
- Limiter autant que possible les dépendances à du matériel ou du logiciel spécifique qui pourrait ne pas fonctionner dans un cloud
- Tolérance aux pannes (fault tolerance) intégrée
- Ne pas stocker les données en local, mais plutôt :
- Base de données
- Stockage bloc
- Stockage objet
- Utiliser des outils de journalisation standards
Modularité
- Philosophie Unix (Keep It Simple Stupid)
- Multiples composants de taille raisonnable
- Couplage faible et interface documentée
Passage à l’échelle
- Pets versus Cattle
- Vertical vs Horizontal
- Scale up/down vs Scale out/in
- Plusieurs petites instances plutôt qu’une seule grosse
Stateful vs stateless
- Beaucoup de stateful dans les applications legacy
- Nécessite de partager l’information d’état lorsque plusieurs workers
- Le stateless élimine cette contrainte
Tolérance aux pannes
- Les APIs du cloud sont hautement disponibles
- Le cloud ne garantit pas la haute disponibilté de l'application
- L’application prend en charge sa propre tolérance aux pannes
Modèles de déploiement
- Blue-Green (attention aux quotas)
- Rolling
- Canary
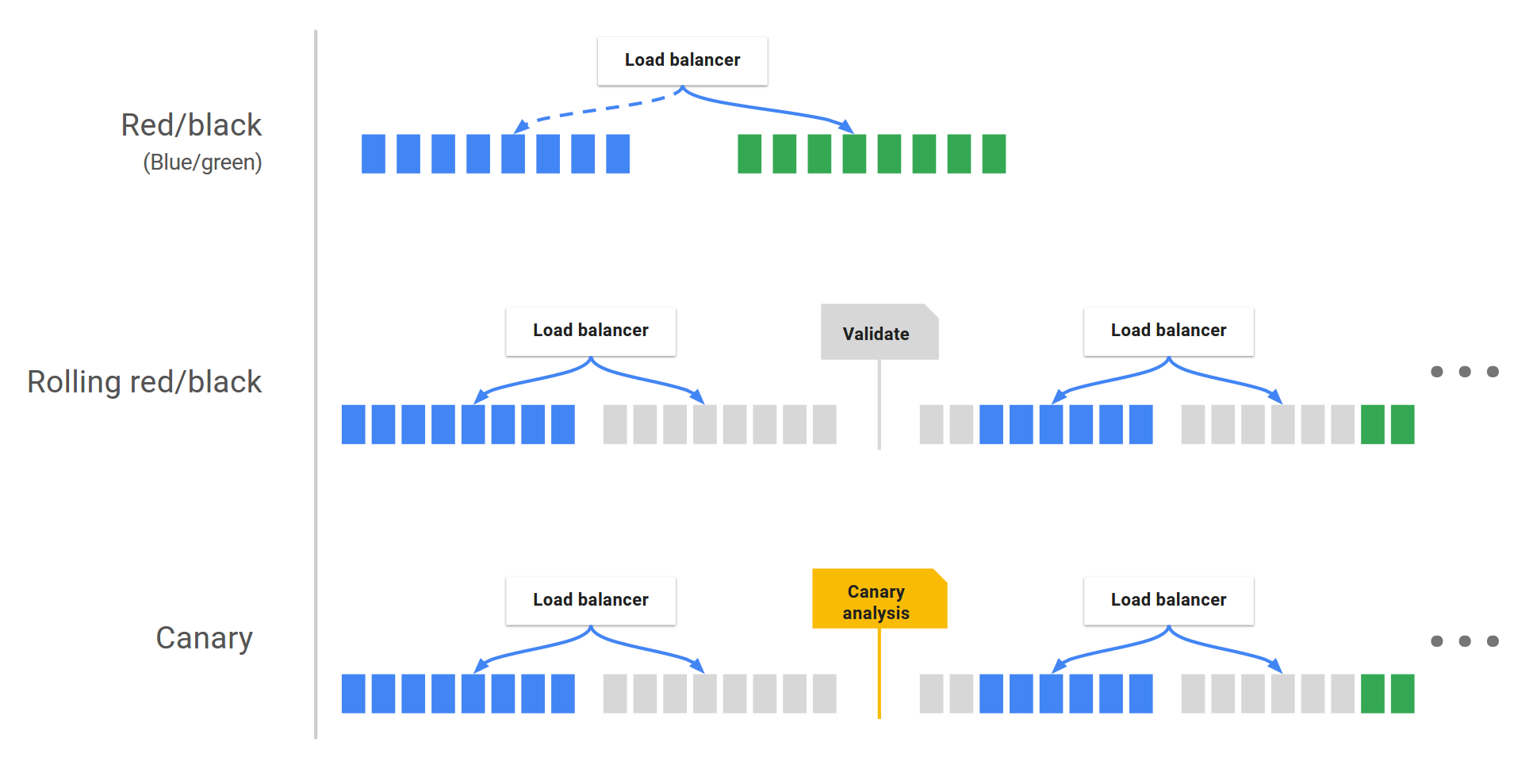
Stockage des données
- Base de données relationnelle
- Base de données NoSQL
- Stockage bloc
- Stockage objet
- Stockage éphémère
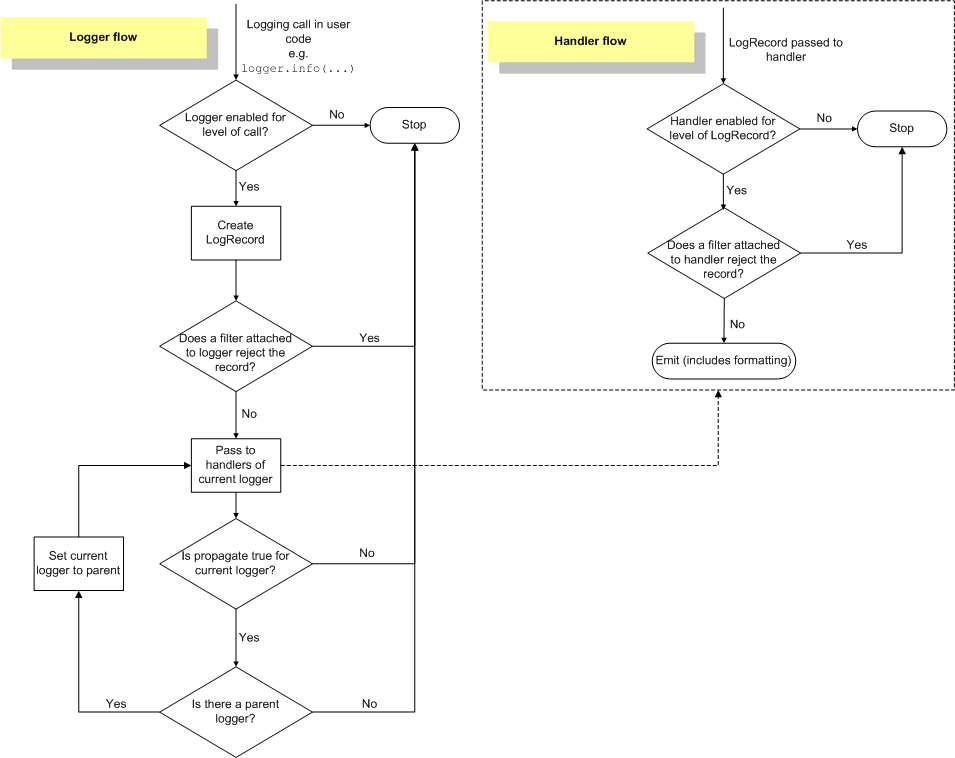
Gestion des logs
- Rester "applicatif"
- Enrichir les logs
- Ne pas présupposer le backend de traitement -> dans la conf
Exemple en python
appLog.conf:
[logger_myapp]
qualname=mycompany.myapp
level=INFO
handlers=console
propagate=0app.py:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import logging
log = logging.getLogger('mycompany.myapp.maintask')
log.info('Main worker started')2018-12-24 22:20:02 INFO appuser Main worker startedLogging flow
Migration des applications legacy
- Rappel des enjeux
- Migrer ou non : critères de décision
Concevoir une infra pour le cloud
L'infra au service de son application
- Souplesse
- Résilience
- Performance
- Opérabilité
Une infra, ça évolue !
- Dimensionnement des clusters
- Maintenance des O.S. « guest » et du middleware
- Règles SSI : segmentation réseau, filtrage de flux, proxys, bastions, annuaires
- Ajout de nouveaux services
Mécaniser, automatiser, industrialiser
- Le niveau d'anxiété des comités face à la décision de déployer est inversement proportionnelle à la fréquence des MEP => cercle vicieux
- (re)Construire, faire évoluer et maintenir les infras hébergées dans le cloud
- Reconstruction totale ou partielle à la demande
- Reproductibilité
- C'est Automagique !
Automatisation
- Mécaniser la gestion de l’infrastructure : indispensable
- Automatiser la gestion de l’infrastructure : un plus !
- Création des ressources
- Configuration des ressources
Infrastructure as Code
- L'infra s'appréhende comme du code
- Travailler comme un développeur
- Décrire son infrastructure sous forme de code (Heat, Terraform)
- Suivre les changements dans un VCS (git), qui devient la référence
- Mettre en oeuvre un système d'intégration et de déploiement continus (CI/CD)
Approche de Heat
- Un service <-> une API OpenStack
- Notions de stack et description YAML
- Précautions d'usage (stack update)
- Cas d'usage type
Exemple Heat
---
heat_template_version: 2018-08-31
description: A single nova instance
parameters:
flavorName:
type: string
resources:
instance:
type: OS::Nova::Server
properties:
name: MonInstance
image: debianStretchOfTheDay
flavor: {get_param: flavorName}
key_name: MaCleSSH
outputs:
instanceId:
value: {get_resource: instance}Approche de Terraform
- L'aspect "cloud agnostique"
- Le DSL de Terraform
- L'exigence Infra as Code (terraform.tfstate)
- Cas d'usage type
Exemple Terraform
# A single nova instance
# Configure the OpenStack Provider
provider "openstack" {
user_name = "MyName"
tenant_name = "MyTenant"
password = "MyPwd"
auth_url = "http://myauthurl:5000/v2.0"
region = "RegionOne"
}
resource "openstack_compute_instance_v2" "MonInstance" {
name = "MonInstance"
count = "1"
image_name = ""
flavor_name = "${var.flavor}"
key_pair = "MaCleSSh"
}Agilité et CI/CD appliquées à l'infra
- Style de code
- Vérification de la syntaxe
- Tests unitaires
- Tests d'intégration
- Tests fonctionnels de bout en bout
Tolérance aux pannes
- Notion de résilience
- Load balancers
- Floating IPs
- Groupes de serveurs stateless
- Healthchecks
Mise à l'échelle / élasticité horizontale
- Groupe d’instances similaires, autoscaling group
- Nombre d’instances variable
- Scaling automatique en fonction de métriques
Supervision
- Prendre en compte le cycle de vie des instances : DOWN != ALERT
- Monitorer les services plutôt que les serveurs
- Oublier les adresses IP ! Exposer un web service
- Prévoir un healthcheck fonctionnel (use case "métier")
Backup, PCA
- Infrastructure : être capable de reconstruire n'importe quel environnement à tout moment
- Données (de l'application, logs) : utiliser les modes de stockage bloc (volumes) et objet (dossiers)
Gérer ses images
- Utilisation d’images génériques et personnalisation à l’instanciation (cloud-init)
- Création d’images offline :
- from scratch : diskimage-builder (TripleO)
- from scratch avec des outils spécifiques aux distributions (
openstack-debian-imagespour Debian) - modifiées avec libguestfs, virt-builder, virt-sysprep
- Création d’images via une instance :
- automatisation possible avec Packer, Terraform, le CLI ou les API du IaaS
- Golden images
Conclusion
Pour conclure
- Le cloud révolutionne l’IT
- OpenStack est le projet libre phare sur la partie IaaS
- Déployer OpenStack n’est pas une mince affaire
- L’utilisation d’un cloud IaaS implique des changements de pratique
- Les métiers d’architecture logicielle et infra évoluent
Comment implémenter un service de Compute